 |
|
Introduzione agli algoritmi genetici
L’idea di applicare i principi dell’evoluzionismo
naturale a sistemi artificiali nacque più di tre decenni fa ed
ha avuto un grande consenso ed un grande sviluppo di recente.
Oggi il loro impiego è assai frequente in diversi campi, dall’ottimizzazione
di sistemi all’apprendimento automatico, dallo studio dei
sistemi sociali ed economici a quelli biologici (Cfr. [Mit96]).
L’idea di base è quella codificare la soluzione di un
problema sotto forma di una stringa di simboli detta genoma
(genome) e di utilizzare un popolazione di dimensione
costante di individui, ciascuno dei quali rappresentato da una
stringa diversa (quindi una diversa possibile soluzione per il
problema), e fare evolvere questa popolazione secondo i
meccanismi dell’evoluzione biologica, al fine di ottenere la
migliore soluzione al problema.
Lo spazio di tutte le possibili soluzioni del problema dato è
detto spazio delle soluzioni (search space).
In genere gli algoritmi genetici sono applicati a problemi in cui
lo spazio delle soluzioni è troppo ampio per essere esplorato
per intero.
L’insieme dei simboli utilizzati per codificare il genoma può
essere un semplice codice binario (come in [Hol75]) o, come
proposto più recentemente un intero codice alfanumerico o
composto da numeri reali.
Un algoritmo genetico standard procede nel seguente modo: una
popolazione di individui viene generata in modo casuale o in base
a informazioni note. Ad ogni passo evolutivo, detto generazione
(generation), tutti gli individui vengono decodificati e
valutati secondo una particolare funzione dipendente dal problema
in esame detta funzione di fitness che
attribuisce a ciascuno di essi un valore detto appunto fitness
che da una misura di come l’individuo si avvicina alla
soluzione del problema.
La fase successiva consiste nella selezione
degli individui che dovranno formare la nuova generazione. La
selezione di un individuo dipende dal suo valore di fitness (cioè
quanto l’individuo è “buono” a risolvere il
problema): un valore più alto di fitness corrisponde ad una
maggiore possibilità di essere scelto come genitore
(parent) per creare la nuova generazione. Uno dei
criteri più utilizzati è quello di Holland (in [Hol75]) che
attribuisce una probabilità di scelta proporzionale al fitness.
Grazie al meccanismo della selezione, solo gli individui migliori
hanno la possibilità di riprodursi e quindi di trasmettere il
loro genoma alle generazioni successive.
Per la creazione di nuovi individui ad ogni generazione si
utilizzano due operazioni ispirate dall’evoluzionismo
biologico: il crossover e la mutazione.
Una volta individuati una coppia di genitori con il meccanismo
della selezione, i loro genomi possono andare incontro a ciascuna
delle due operazioni con probabilità rispettivamente Pcross
(probabilità di crossover per coppia di individui, detta crossover
rate) e Pmut (probabilità di mutazione per gene,
detta mutation rate).
Se due genitori vanno incontro a crossover, il loro genoma viene
scambiato da un certo punto in poi (stabilito casualmente),
altrimenti rimangono inalterati. A questo punto, ogni simbolo del
loro genoma può andare incontro a mutazione con la probabilità
stabilita. Se un simbolo muta, esso viene semplicemente cambiato
in un altro scelto a caso.
I due individui che si ottengono così rappresentano i discendenti
(offspring) dei due genitori, e prenderanno il loro
posto nella prossima generazione. Se due genitori non vanno
incontro ne a crossover ne a mutazione, i discendenti saranno
identici ai genitori. Si ripete il processo fino ad ottenere un
numero di discendenti uguale a quello dei genitori.
Ottenuta la nuova generazione, si ripete il processo un numero
opportuno di volte, ottenendo di volta in volta una popolazione
che mediamente ha un valore di fitness elevato, al limite ottimo.
Il genoma degli individui così ottenuti codifica la soluzione
del problema cercata.
Tuttavia, bisogna tenere presente che essendo un processo
essenzialmente stocastico, non è garantita ne la convergenza, ne
il raggiungimento della soluzione ottima. Spesso infatti la
popolazione si stabilizza su “ottimi locali” che
possono differire da quello assoluto.
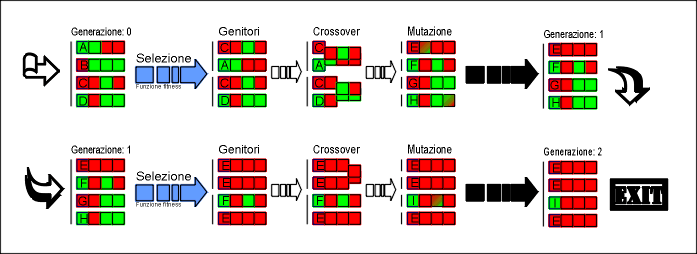
La figura seguente mostra un esempio tratto da [Mit96], in cui l’obbiettivo
è ottenere un genoma composto solo da uni. Il genoma è
codificato con un codice binario (nella figura rosso=1, verde=0),
e la funzione di fitness è data dal numero di uni contenuti in
ogni individuo. Si nota che dopo solo due generazioni quasi tutta
la popolazione ha raggiunto l’obbiettivo prefissato.
Un programma che implementa un algoritmo genetico è schematizzabile con il seguente pseudocodice:
inizializza la vecchia_popolazione (assegnando un genoma casuale a ciascun individuo)
ripeti per il numero di generazioni voluto
inizializza nuova_popolazione (nessun individuo)
calcola il valore di fitness di ciascun individuo
ripeti (numero individui)/2 volte
seleziona casualmente due individui
se rnd < Pcross applica crossover
se rnd < Pmut applica mutazione
aggiungi i due individui a nuova_popolazione
fine ripetizione popolazione
copia nuova_generazione in vecchia_generazione
fine ripetizione generazioni
Non esistono dei risultati teorici certi riguardo
al numero ottimale della popolazione per un determinato problema,
così come non è chiaro quale sia il metodo migliore per
scegliere il valore delle probabilità di crossover e mutazione.
In genere si procede per via empirica a seconda delle
caratteristiche del particolare problema. Alcuni valori tipici
sono:
- popolazione: da 100 a 10000 (dipende molto dal problema);
- Pcross: circa 0.8;
- Pmut: attorno a 0.01.
Bibliografia essenziale:
[Hol75] J. H. Holland. Adaptation in Natural
and Artificial Systems. The University of Michigan Press,
1975
[Mit96] M. Mitchell. An Introduction to
Genetic Algorithms. MIT Press, 1996.
Casa dolce casa! |