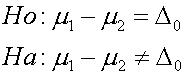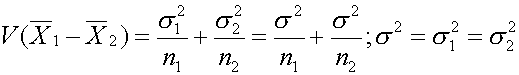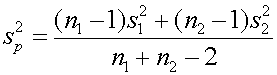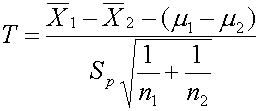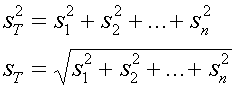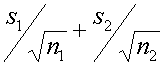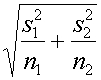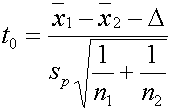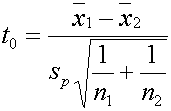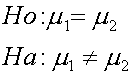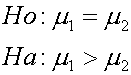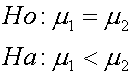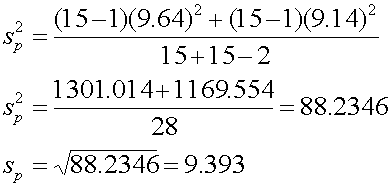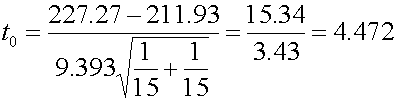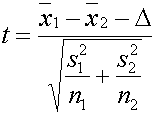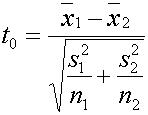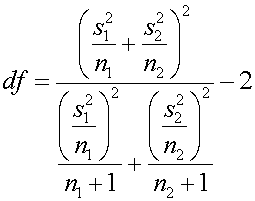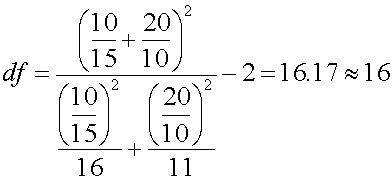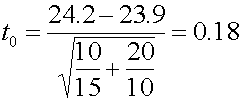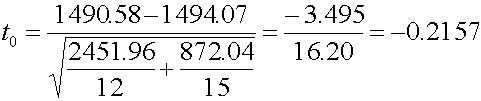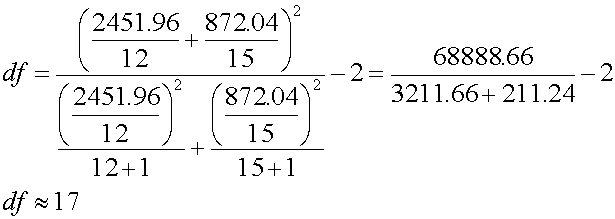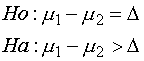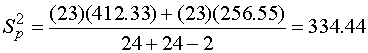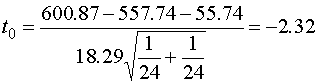การทดสอบความแตกต่างระหว่างค่ากลางของสองประชากรที่มีการกระจายแบบปกติและอิสระต่อกัน (Test Concerning a Difference Between Two Means of two normal population : Independent Samples) โดยส่วนมากเราต้องการทดสอบสมมติฐานเกี่ยวกับความแตกต่างของสองประชากร ซึ่งถ้าใช้คำว่าประชากร บางคนอาจจะมองไม่เห็นภาพ ถ้าจะอธิบายว่า เราต้องการพิสูจน์ ความแตกต่างของสองกระบวนการ (Processes) หรือต้องการพิสูจน์ผลการทดลองของสองวิธีการ ( Treatments) ว่าตัวแปรหรือผลการทดลองที่เราสนใจ (Response) มีความแตกต่างกันอย่างมีนัยสำคัญหรือไม่ หรือว่าไม่แตกต่างกัน ตัวอย่าง ต้องการพิสูจน์ ว่าต้นกล้าของพืช A ที่เพาะชำโดยใช้ส่วนผสมของดินแบบสูตร 1 สูงเท่า น้อยกว่า หรือ มากกว่า เมื่อเพาะชำพืชแบบ A นี้โดยใช้ส่วนผสมดิน แบบสูตร 2 เป็นต้น คำว่าประชากร ในตัวอย่างนี้คือค่าส่วนสูงของต้นกล้าของพืช A แน่นอนว่าคนที่ทำการศึกษาคงไม่ทดลองแค่ต้นเดียวแน่ๆ นั่นคือเขาจะต้องทดลองปลูกต้นกล้าพืช A ในส่วนผสมดิน แต่ละสูตร มากพอสมควร ซึ่งการที่เขาเพาะกล้าพืช โดยใช้สูตรของดินเพาะปลูกต่างกัน 2 สูตร นั่นก็คือมี 2 Treatments นั่นเอง หรืออาจจะมองว่าเป็น Process การเพาะกล้าไม้ 2 Process ก็ได้เช่นเดียวกัน คำว่า อิสระในตัวอย่างก็คือ แต่ละ Treatment ต้นกล้าซึ่งเป็นสิ่งที่ผู้ทดลองสนใจ ไม่ใช่ต้นเดียวกัน แต่ละต้นก็มีอิสระในการงอก ไม่เกี่ยวข้องกัน แต่ถ้าดูดีๆ ผู้ทำการทดลองจะต้องกำจัดความแตกต่าง หรือปัจจัยอื่นๆ ที่อาจจะมีผลกระทบกับผลการทดลองออกไปให้มากที่สุด เช่น จะต้องเลือกดินก่อนใส่ส่วนผสมเหมือนกัน เลือกชนิดของพืชที่จะเพาะเป็นแบบเดียวกัน เมล็ดพันธ์ถูกคละกัน ก่อนแบ่งออกเป็นสองกลุ่มโดยวิธีการสุ่ม เริ่มเพาะวันเดียวกัน เวลาเดียวกัน เก็บไว้ในโรงเพาะชำเดียวกัน รดน้ำ ควบคุม อุณหภูมิ ให้เหมือนกัน พูดง่ายๆคือ ปัจจัยอื่นๆ นอกจากสูตรผสมของดินที่ใช้เพาะ ผู้ทดลองจะต้องควบคุมให้เหมือนกันให้มากที่สุด แม้แต่สุดท้าย เมื่อถึงกำหนดวัดส่วนสูง จะต้องวัดโดยใช้เครื่องมือวัดอันเดียวกัน คนเดียวกัน เวลาวัดเดียวกัน เพื่อกำจัดความแตกต่างอื่นๆ ที่เราไม่สนใจอยากรู้ออกไปให้หมด ให้เหลือแต่ความแตกต่างที่เราต้องการเห็นผลกระทบ คือสูตรผสมของดินเพาะกล้า การกระทำดังกล่าวมาเราเรียกว่า Treatment ในวิชาสถิติ คำว่า Treatment นี้ได้มาจากการนำศาสตร์แขนงนี้ไปประยุกต์ใช้ในการทำวิจัยด้าน พืชศาสตร์ จึงเกิดคำศัพท์ Treatment ขึ้นมา แม้ภายหลังมีการวิจัยด้านวิศวกรรม หรือด้านอื่นๆ คำว่า Treatment ก็ยังถูนำมาใช้อย่างกว้างขวาง จนถึงบัดนี้ เมื่อผู้ทำการศึกษา ได้วัดค่าส่วนสูงของต้นกล้า มาแล้ว เราจะกำหนดว่า m1 : คือค่าเฉลี่ยของ Population 1 หรือในตัวอย่างจะเป็นค่าส่วนสูงโดยเฉลี่ยของต้นกล้าโดยใช้สูตรผสมแบบที่ 1 m2 : คือค่าเฉลี่ยของ Population 2 หรือในตัวอย่างจะเป็นค่าส่วนสูงโดยเฉลี่ยของต้นกล้าโดยสูตรผสมแบบที่ 2 ในทางปฏิบัติ เนื่องจากผู้ทดลองได้ทำการสุ่มตัวอย่างออกมาวัดค่าส่วนสูง ซึงแน่นอนว่าเขาก็ไม่สามารถวัดต้นกล้าพืช ได้ทุกต้น เมื่อเป็นเช่นนี้จึงเท่ากับเป็นการ อนุมาน ( Inference ) ไปหาประชากรต้นกล้าพืชทั้งหมด โดยผ่านการวิเคราะห์ข้อมูลของตัวอย่าง เราจะกำหนดให้ n1 : คือจำนวนตัวอย่างกลุ่มที่ 1 หรือในตัวอย่างนี้ก็คือจำนวนตัวอย่างต้นกล้าพืช ที่ใช้สูตรผสมแบบที่ 1 n2 : คือจำนวนตัวอย่างกลุ่มที่ 2 หรือในตัวอย่างนี้ก็คือจำนวนตัวอย่างต้นกล้าพืช ที่ใช้สูตรผสมแบบที่ 2 X1 : คือค่าเฉลี่ยตัวอย่างกลุ่มที่ 1 หรือในตัวอย่างนี้ก็คือส่วนสูงโดยเฉลี่ยของตัวอย่างต้นกล้าพืช ที่ใช้สูตรผสมแบบที่ 1 X2 : คือค่าเฉลี่ยตัวอย่างกลุ่มที่ 2 หรือในตัวอย่างนี้ก็คือส่วนสูงโดยเฉลี่ยของตัวอย่างต้นกล้าพืช ที่ใช้สูตรผสมแบบที่ 2 S21 : คือค่า Variance จากตัวอย่างกลุ่มที่ 1 หรือในตัวอย่างนี้ก็คือค่า Variance ของส่วนสูงของตัวอย่างต้นกล้าพืช ที่ใช้สูตรผสมแบบที่ 1 S22 : คือค่า Variance จากตัวอย่างกลุ่มที่ 2 หรือในตัวอย่างนี้ก็คือค่า Variance ของส่วนสูงของตัวอย่างต้นกล้าพืช ที่ใช้สูตรผสมแบบที่ 2
การทดสอบสมมติฐาน ในการทดสอบสมมติฐานเราจะแยกการทดสอบออกเป็นสองกรณี คือ กรณีค่า Variance ของข้อมูลทั้งสองกลุ่มเท่ากัน และกรณีค่า Variance ไม่เท่ากัน กรณี Variance เท่ากัน ( s21=s22) สมมติเราต้องการทดสอบสมมติฐานที่ว่าค่า m1= m2หรือไม่ แน่นอนว่าเราจะรู้ได้ว่าเท่าหรือต่างกันเราสามารถหาจากผลต่าง m1- m2 ถ้าผลต่างเท่ากับ 0 (ศูนย์) ก็บอกได้ว่าสมมติฐานนั้นเป็นจริง แต่แน่นอนว่า ผลต่างนั้นโอกาสจะเท่ากับ 0 เป็นไปได้ยาก แต่บางครั้งความรู้สึกของผู้ที่กำลังทดสอบสมมติฐานจะบอกว่า แม้ไม่เท่ากับ 0 แต่เขาก็ยังจะยอมรับได้ว่า m1= m2 ยังเป็นจริงอยู่ นั่นก็แปลว่า เราจะยอมรับให้ ผลต่าง อยู่ในช่วงๆ หนึ่ง รอบๆ ค่า 0 ในทางบวกและลบ เท่าๆกัน ดังสมการ
เมื่อเป็นเช่นนี้ ค่า D ก็จะเป็น Interval และค่าจะมีลักษณะเป็น t- Distribution ดังนั้นเมื่อเราจะทดสอบสมมติฐานความแตกต่างของ m1และ m2 เราจะกระทำผ่านผลต่างดังกล่าว ว่ามีค่าไม่เท่ากับ 0 อย่างมีนัยสำคัญหรือไม่นั่นเอง ถ้าสมมติมีข้อมูลที่มีการกระจายแบบปกติ (Normal) อยู่สองข้อมูลที่ไม่รู้ค่าที่แท้จริงของ m1และ m2 ในขณะที่ไม่รู้ค่าที่แท้จริงของ s21และ s22 รู้แต่ว่า s21=s22 เราต้องการทดสอบสมมติฐาน
เรากำหนดตัวประมาณการค่ากลางของประชากรจากค่าเฉลี่ยของตัวอย่าง ดังนี้
เรากำหนดตัวประมาณการค่า Variance ของประชากรจาก Variance ของตัวอย่าง ดังนี้
แต่ถ้าเรารู้ว่า s21=s22 แปลว่า S21=S22 ด้วยเช่นกัน ดังนั้น ถ้าเรากำหนดให้ S2P เป็น Pooled estimator ของ s2 ดังนั้น
จากหัวข้อ 1-Sample t หรือการทดสอบ ค่ากลางของหนึ่งประชากร กับค่าคงที่ มีสมการว่า
เมื่อเราจะคิดแบบสองประชากรจะได้สมการเป็น
อาจจะสงสัยว่าทำไมตัวส่วนจึงดูแปลกๆ เพราะโดยหลักแล้วค่า Standard deviation นั้นไม่สามารถจะนำมาบวกกันโดยตรงได้ และไม่สามารถจะนำมาลบกันได้ด้วย (เมื่อจำนวนข้อมูลเพิ่ม Standard deviation มีแต่เพิ่มอย่างเดียวไม่มีลดลง )
สมการดังข้างบนจึงไม่สามารถใช้ได้ จะต้องใช้สมการดังนี้ต่อไปนี้ถึงจะถูกต้อง
ดังนั้นการบวกกันดังต่อไปนี้จึงผิด
จะต้องเป็นดังนี้ถึงจะถูกต้อง
เมื่อกำหนดให้
ดังนั้น
ซึ่ง t คือตัวทดสอบสถิติของ กรณีการทดสอบค่ากลางของสองกลุ่มตัวอย่าง (ประชากร) ในกรณีที่เราถือว่า D = 0 ดังนั้น จะได้ว่า
เมื่อใช้ t-Distribution ในการทดสอบสมมติฐาน จึงจำเป็นต้องรู้ค่า Degree of freedom
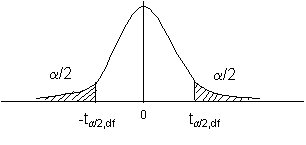
การตั้งสมมติฐาน การตั้งสมมติฐานมีหลักการเช่นเดียวกันกับกรณีการทดสอบค่ากลางของหนึ่งประชากรกับค่าคงที่ ดังต่อไปนี้ ในกรณีทดสอบสองด้าน ( Two-tailed )
t- Distribution ที่จะใช้สำหรับทดสอบนี้ก็คือ ผลต่าง m1= m2 ซึ่งจริงๆ ควรจะเท่ากับ 0 เราถึงจะยอมรับสมมติฐานหลัก แต่เราใช้หลัก Confidence interval ก็จะได้ว่า ผลต่างที่ไม่เท่ากับ 0 แต่น้อยหรือมากกว่า ในระดับหนึ่งภายใน Interval นั้นเราจะยังยอมรับสมมติฐานหลักอยู่
เราจะยังยอมรับสมมติฐานหลัก H0:m1=m2 ถ้า
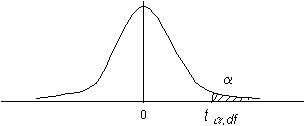
ในกรณีทดสอบด้านเดียว ( One-tailed ) ในกรณีที่เราให้สมมติฐานทางเลือก (Alternative hypothesis) เป็นมากกว่าหรือน้อยกว่า เราเรียกว่าการทดสอบสมมติฐานแบบ One tailed ซึ่งเป็นดังต่อไปนี้ ทดสอบด้านมากกว่า
เมื่อเทียบกับ t-Distribution จะเป็นดังรูปต่อไปนี้
เราจะยังยอมรับสมมติฐานหลัก H0:m1=m2 ถ้า
ถ้าทดสอบด้านน้อยกว่า
เมื่อเทียบกับ t-Distribution จะเป็นดังรูปต่อไปนี้
เราจะยังยอมรับสมมติฐานหลัก H0:m1=m2 ถ้า
จะเห็นว่า วิธีการทดสอบสมมติฐาน การทดสอบค่ากลางของสองประชากรก็จะคล้ายกับกรณีทดสอบค่ากลางประชากรเดียว แตกต่างกันในรายละเอียดบ้างนิดหน่อย ที่สำคัญผู้ที่จะทำการทดสอบสมมติฐานจะต้องมั่นใจว่า 1. ข้อมูลของทั้งสองกลุ่มที่จะนำมาทดสอบสมมติฐานต้องเป็นอิสระต่อกัน และแต่ละตัวข้อมูลในกลุ่มต้องถูกเก็บตัวอย่างออกมาโดยการสุ่ม 2. ข้อมูลตัวอย่างทั้งสองกลุ่มดังกล่าว จะต้องมีการกระจายตัวเป็นแบบปกติ (Normal distribution) เท่านั้น การทดสอบสมมติฐานความแตกต่างของค่ากลางของสองประชากรอิสระนี้ รู้จักในชื่อง่ายๆว่า 2-Sample t test ตัวอย่าง จากหัวข้อที่ผ่านมา ผู้วิจัยต้องการพิสูจน์ ว่าต้นกล้าของพืช A ที่เพาะชำโดยใช้ส่วนผสมของดินแบบสูตร 1 สูงเท่า น้อยกว่า หรือ มากกว่า เมื่อเพาะชำพืชแบบ A นี้โดยใช้ส่วนผสมดิน แบบสูตร 2 โดยต้องการความเชื่อมั่นในผลการทดสอบที่ 95% จึงทำการสุ่มกล้าไม้พืช A จากกลุ่มที่ใช้สูตรผสมดินแบบที่ 1 และ 2 ออกมากลุ่มละ 15 ตัวอย่าง(ต้น) แล้ววัดส่วนสูงของต้นกล้า โดยวัดจากโคนลำต้นส่วนที่เริ่มโผล่พ้นดิน จนถึงส่วนของใบ ที่สูงที่สุด โดยไม่มีการแตะต้องใบของต้นกล้าไม้ในขณะวัด ปรากฏผลการวัดส่วนสูงดังนี้ (หน่วยเป็น มิลลิเมตร) โดยที่ข้อมูล Group 1 คือส่วนสูงของต้นกล้าไม้ ที่เพาะโดยใช้สูตรผสมดินแบบที่ 1 และข้อมูล Group 2 คือส่วนสูงของต้นกล้าไม้ ที่เพาะโดยใช้สูตรผสมดินแบบที่ 2
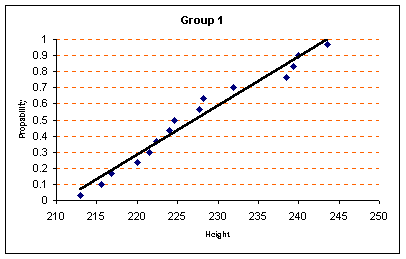
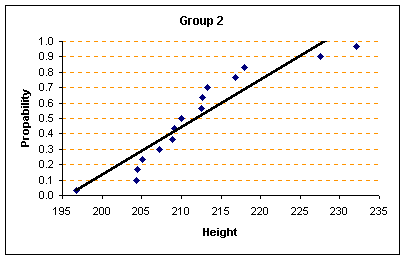
1. เริ่มแรกต้องทำการทดสอบ ข้อมูลทั้งสองกลุ่มเสียก่อนว่ามีการกระจายเป็นแบบ Normal distribution หรือไม่ (โปรดดูในหัวข้อการทดสอบความเป็นการกระจายแบบปกติ Normality Test) จากข้อมูลทั้งสองกลุ่มผลการทดสอบ ได้ดังนี้
จากกราฟ Propability plot ของทั้งสองกลุ่มจะสรุปได้ว่า ข้อมูลส่วนสูงของต้นกล้าพืชทั้งสองกลุ่มที่สุ่มตัวอย่างมานั้น มีการกระจายเป็นแบบปกติ (Normal distribution) 2. คำนวณหาค่า Sample Statistic ของข้อมูลทั้งสองกลุ่ม ได้ดังนี้ ( ใช้โปรแกรม Minitab ) จะได้ดังนี้ Descriptive Statistics: Group_1, Group_2 Variable N Mean StDev Group_1 15 227.27 9.64 Group_2 15 211.93 9.14
หากใช้ Microsoft Excel โดยใช้ Analysis Tools หา Summary Descriptive จะได้ดังนี้ (โปรดดูวิธีการในหัวข้อการประยุกต์ใช้ Microsoft Excel )
3. กำหนดสมมติฐาน
โดยที่ m1 คือค่าเฉลี่ยส่วนสูงของต้นกล้าที่เพาะโดยใช้สูตรผสมดินแบบที่ 1 และ m2 คือค่าเฉลี่ยส่วนสูงของต้นกล้าที่เพาะโดยใช้สูตรผสมดินแบบที่ 2 4. เลือกตัวทดสอบสมมติฐาน
5. คำนวณค่า Sp จากสมการ
6. คำนวณค่า t จากสมการ
7. คำนวณหา df
df= 28 8. สรุปผลการทดสอบสมมติฐาน จากตาราง t-Distribution ที่ df=28 และ a=0.025 (มาจาก 0.05/2 ) จะได้ t0.025,28= 2.048 ดังนั้น เมื่อ t0 >t0.025,28 จึงปฏิเสธ สมมติฐาน หลัก H0:m1=m2 นั่นคือจากผลการทดลองสรุปว่า ต้นกล้าพืช A ที่ปลูกโดยส่วนผสมดินสองสูตร มีส่วนสูงต่างกันอย่างมีนัยสำคัญ ถ้าใช้โปรแกรม Minitab ในการคำนวณจะได้ดังนี้ Two-sample T for Group_1 vs Group_2 N Mean StDev SE Mean Group_1 15 227.27 9.64 2.5 Group_2 15 211.93 9.14 2.4 Difference = mu Group_1 - mu Group_2 Estimate for difference: 15.33 95% CI for difference: (8.31, 22.36) T-Test of difference = 0 (vs not =): T-Value = 4.47 P-Value = 0.000 DF = 28 Both use Pooled StDev = 9.39
เมื่อค่า P-Value น้อยกว่า a (0.05) จึงปฏิเสธ สมมติฐาน หลัก H0:m1=m2 นั่นคือจากผลการทดลองสรุปว่า ต้นกล้าพืช A ที่ปลูกโดยส่วนผสมดินสองสูตร มีส่วนสูงต่างกันอย่างมีนัยสำคัญ ้ถ้าใช้โปรแกรม Microsoft Excel ในการคำนวณจะได้ดังนี้
จาก Microsoft Excel ผลการวิเคราะห์จะให้ค่า P-value และ t - Critical ( ta/2,df) ออกมาทั้ง การทดสอบแบบ Two-tailed และ One - tailed ด้วย ค่าที่เราใช้ในการสรุปผลการทดสอบ สามารถใช้ 1. P-Value : โดย ถ้า P-Value น้อยกว่า a ก็ปฏิเสธสมมติฐานหลัก H0:m1=m2 2. เปรียบเทียบ ค่า t (Statistic) ถ้ามากกว่า t Critical ก็ปฏิเสธสมมติฐานหลัก H0:m1=m2 ทั้งสองวิธีนี้จะสรุปผลไปในแนวทางเดียวกันเสมอ ทั้งเราสามารถเลือกใช้เพียงวิธีใดวิธีหนึ่งในการสรุปผลการทดสอบสมมติฐาน
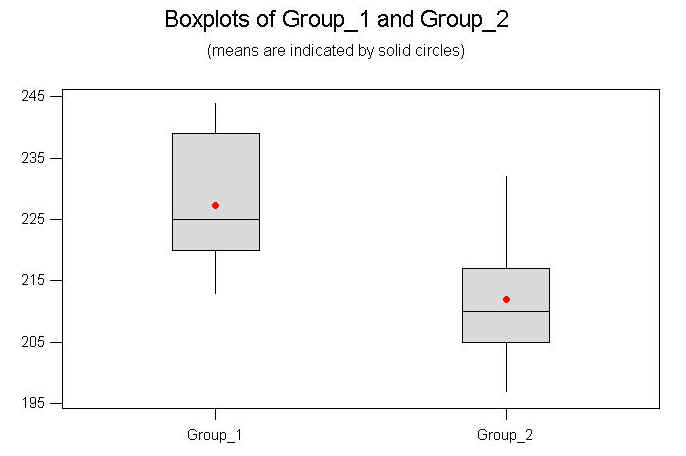
ถ้าผู้ทำการทดลองอยากสรุปว่า แล้วสูตรผสมดินเพาะชำนี้ สูตรไหนดีกว่า ก็ให้ย้อนกลับไปดูค่าส่วนสูงโดยเฉลี่ย จากข้อมูลจะพบว่า Group 1 จะมีส่วนสูงเฉลี่ยของต้นกล้าพืช A สูงกว่า จึงสรุปว่าสูตรผสมดินสูตร 1 ทำให้ต้นกล้าไม้โตเร็วกว่า สูตรที่ 2 แต่จะไม่สรุปว่าดีกว่าหรือไม่ เพราะคำว่าดีกว่าอาจจะต้องรวมถึง ใช้น้อยกว่าแต่ให้ผลผลิตมากกว่า ต้นกล้าไม้ทนต่อโรคพืชมากกว่า และอื่นๆ อีกหลายปัจจัย ซึ่งจะต้องเก็บข้อมูล ตามวัตถุประสงค์ที่ต้องการทราบ ทั้งนี้ส่วนสูงของต้นกล้าถือเป็นเพียงปัจจัยหลักอันหนึ่งเท่านั้นที่ใช้เป็นตัวชี้วัด เกร็ดน่ารู้และน่าคิด จากวิธีการทดสอบสมมติฐานที่ผ่านมาพอจะบอกได้ว่า เราตัดสินใช้ด้วยตัวเลข คือดูค่า P-value หรือไม่ก็เปรียบเทียบค่า t (statistic) กับค่า t- critical ซึ่งเราเรียกว่าการตัดสินใจเชิงปริมาณ ( Quantitative) จากข้อมูลดังตัวอย่างที่ผ่านมา หากเรานำข้อมูล Group 1 และ Group 2 มาแสดงโดยใช้ Box plot จะได้ดังนี้
เมื่อท่านดูกราฟนี้แล้วท่านบอกได้ทันทีที่เห็นเลยว่า ส่วนสูงของต้นกล้าพืช A Group 1 สูงกว่า Group 2 แน่ๆ โดยไม่ต้องมีการคำนวณหาค่า t หรือ P-Value เลย นอกจากนั้นท่านยังเห็นลักษณะการกระจายของข้อมูล ค่าเฉลี่ยอยู่ตรงไหน สองกลุ่มนี้แตกต่างกันมากน้อยแค่ไหน ลักษณะเช่นนี้เราเรียกว่าการตัดสินใจโดยใช้ข้อมูลเชิงคุณภาพ (Qualitative) ผมเชื่อว่าผู้อ่านหลายท่านเห็นด้วยกับผมที่ว่า คนส่วนใหญ่จะจมอยู่กับตัวเลข จะต้องใช้ตัวเลขเพื่อเป็นหลักฐานในการสรุปผล โดยหารู้ไม่ว่า เป็นความเข้าใจที่ผิดพลาดอย่างมาก เพราะตามหลักแล้วจะต้องใช้ข้อมูลเชิง Qualitative ก่อน เมื่อให้ผลคลุมเครือ จึงใช้ข้อมูลแบบ Quantitative มาสนับสนุนทีหลัง มีกราฟหลายประเภท ที่ใช้ในการนำเสนอข้อมูล ในเชิงคุณภาพ ได้ดี แล้วท่านละจะเลือกแบบไหน กรณี Variance ไม่เท่ากัน ( s21 ไม่เท่ากับ s22) ในบางสถานะการณ์เราไม่สามารถประมาณให้ค่า variance ของข้อมูลของทั้งสองกลุ่มเท่ากันได้ เพราะค่าแตกต่างกันอย่างชัดเจน ตัวทดสอบสถิติจึงไม่สามารถใช้ได้กับ กรณีค่า Variance เท่ากัน แต่เราจะใช้
ถ้ากำหนดให้ D = 0
เมื่อเป็น t-Distribution ก็จำเป็นต้องหา Degree of freedom จาก
้ ตัวอย่าง ในระหว่างการผลิตวงจรแผงวงจรไฟฟ้าสองแบบ วิศวกรต้องการทดสอบว่า แผงวงจรไฟฟ้าทั้งสองแบบ ต้องการกระแสไฟฟ้าเท่ากันหรือแตกต่างกัน โดยได้ทำการสุ่มเก็บตัวอย่างแผงวงจรไฟฟ้าแบบที่ 1 มาจำนวน 15 ตัวอย่าง และแบบที่ 2 จำนวน 10 ตัวอย่าง ดังรายละเอียดต่อไปนี้ ให้ทดสอบสมมติฐาน โดยกำหนดให้ ระดับความเชื่อมั่นของการทดสอบที่ 90 % Design 1: n1 = 15 X1 = 24.2 mA S21 = 10 Design 2: n2 = 10 X2 = 23.9 mA S22 = 20 1. Parameter ที่ต้องการทดสอบ คือ ค่ากลางของปริมาณกระแสไฟฟ้า ที่แผงวงจรไฟฟ้าต้องการ (m1 , m2) 2. ตั้งสมมติฐาน
3. ระบุค่านัยสำคัญ จากโจทย์ กำหนดความเชื่อมั่นที่ 90% ดังนั้น a=0.10 4. เลือกตัวทดสอบสถิติ คือ
5. หาค่า Degree of freedom จาก
นั่นคือ ถ้า a=0.10 เราจะปฏิเสธสมมติฐานหลัก H0 : m1=m2 ถ้า t0 > ta/2,df หรือถ้า t 0< - ta/2,df จากตาราง t จะได้ t0.05,16=1.746 6. คำนวณหาค่า t0 จาก
7.สรุปผลการทดสอบสมมติฐาน เมื่อ t0 = 0.18 ซึ่งมากกว่า -1.746 และน้อยกว่า 1.746 จึงยอมรับสมมติฐานหลักที่ว่า H0 : m1=m2 นั่นคือ สรุปว่า แผงวงจรทั้งสองแบบ ต้องการกระแสไฟฟ้า ไม่แตกต่างกันนั่นเอง ตัวอย่างโจทย์ หัวหน้าฝ่ายผลิตได้ทำการเก็บค่าน้ำหนักบรรจุของผงซักผ้า ในสายการผลิตขนาด 1500 กรัมต่อกล่อง มาจากสายการบรรจุสองสาย และต้องการพิสูจน์ทราบว่า เครื่องบรรจุผงซักผ้าทั้งสองเครื่องนั้นบรรจุปริมาณผงซักผ้าลงกล่องบรรจุ ในปริมาณเท่ากันหรือแตกต่างกันอย่างไร จึงสุ่มจำนวนตัวอย่างจาก เครื่องบรรจุที่หนึ่งมา 12 กล่อง และจากเครื่องบรรจุที่สองมา 15 กล่อง โดยมีข้อมูลดังนี้
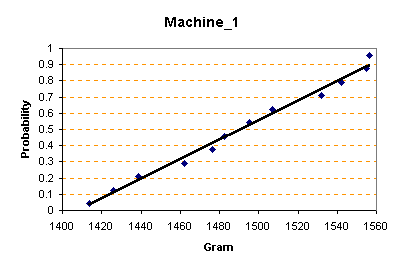
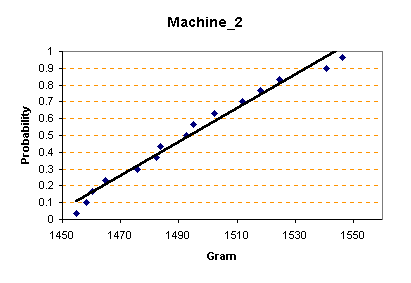
จงทำการวิเคราะห์ และสรุปผลสมมติฐาน โดยกำหนดค่าความเชื่อมั่นของการทดสอบ 90% เริ่มแรกต้องทำการ Qualify ข้อมูลก่อน โดยเริ่มจากการทดสอบ Normality Test โปรดดูหัวข้อ การทดสอบความเป็นการกระจายแบบปกติ (Normality Test) ซึ่งได้ผลดังนี้
จากกราฟของการทดสอบ Normality test ของข้อมูลทั้งสอง บอกได้ว่าข้อมูลมีการกระจายแบบปกติ (Normal Distribution) จึงสามารถจะเริ่มทำการทดสอบต่อไปได้ ต่อไปก็หาค่าสถิติต่างๆ ของข้อมูล ( Descriptive Summary)
การพิสูจน์โดยการคำนวณและเปิดตาราง เริมจากการคำนวณหาค่า t0
ต่อไปก็คำนวณหาค่า Degree of freedom ( df )
นั่นคือ ถ้า a=0.10 เราจะปฏิเสธสมมติฐานหลัก H0 : m1=m2 ถ้า t0 > ta/2,df หรือถ้า t 0< - ta/2,df ็เปิดตาราง t -Table t0 ที่ df=17 , a=0.05 ได้ t0.05,17 = 1.74 เนื่องจาก ค่า t ที่คำนวณได้ -0.2157 ซึ่งมีค่าอยู่ภายใต้ Interval -1.74 ถึง 1.74 ดังนั้นเราจึงยอมรับ สมมติฐานที่ว่า H0 : m1=m2 ซึ่งแปลว่า เครื่องบรรจุผงซักผ้าลงกล่องทั้งสองเครื่องนี้ ให้ขนาดบรรจุในกล่องไม่แตกต่างกัน
หากใช้ Analysis Tools ของ MS-Excel โดยต้องเลือก t-Test: Two-Sample Assuming Unequal Variances จะให้ผลดังนี้
การสรุปผลมีสองวิธีคือ 1. เปรียบเทียบ P-Value กับ a ถ้า P-Value มากกว่า a เราก็ยอมรับสมมติฐานหลัก H0 : m1=m2 ในข้อนี้ ค่า P-Value = 0.8317 ซึ่งมากกว่า 0.10 เราจึงยอมรับสมมติฐานหลัก 2. เปรียบเทียบค่า t-Stat กับค่า t - Critical ถ้าค่า t-Stat มากกว่าค่า t- Critical หรือน้อยกว่าค่าลบ (-) t Critical เราจะปฏิเธสมมติฐานหลัก H0 : m1=m2 แต่ถ้าค่าอยู่ระหว่าง ค่า -t Critical ไปจนถึง +t Critical ก็ยอมรับสมมติฐานหลัก จากผลลัพธ์ของ MS-Excel ได้ค่า t Stat เท่ากับ -0.2157 ซึ่งอยู่ภายใต้ Interval -1.7396 ถึง + 1.7396 เราจึงยอมรับสมมติฐานหลัก ทั้งเราสามารถเลือกใช้เพียงวิธีใดวิธีหนึ่ง ซึ่งจะให้คำตอบที่ถูกต้องและแม้ว่าจะใช้ทั้งสองวิธี ก็จะได้คำตอบออกมาแนวเดียวกันเสมอ
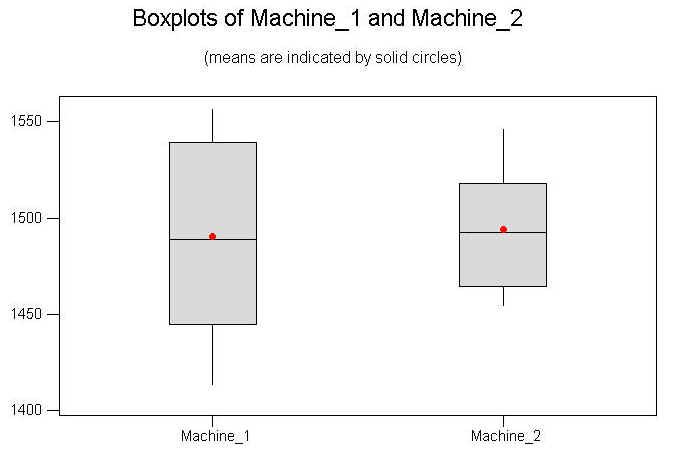
หากใช้โปรแกรม Minitab จะให้ผลดังนี้ Two-sample T for Machine_1 vs Machine_2 N Mean StDev SE Mean Machine_1 12 1490.6 49.5 14 Machine_2 15 1494.1 29.5 7.6 Difference = mu Machine_1 - mu Machine_2 Estimate for difference: -3.5 90% CI for difference: (-31.7, 24.7) T-Test of difference = 0(vs not =): T-Value = -0.22 P-Value =0.832 DF=17
จากผลลัพธ์เมื่อใช้ Minitab ค่า P-Value มากกว่า a (0.10) เราจึงยอมรับสมมติฐานหลัก H0 : m1=m2 ่ทั้งนี้เมื่อเราทำการแสดงค่าของข้อมูลทั้งสองกลุ่มออกมาในรูป Box plot เราจะเห็นว่า ค่าเฉลี่ยใกล้เคียงกันมาก แต่ การกระจายของข้อมูลกลับแตกต่างกัน แต่เนื่องจากว่า t Test ไม่สามารถใช้พิสูจน์ความแตกต่างกันของค่าการกระจายของข้อมูลได้ ผู้ทำการวิเคราะห์ข้อมูลจึงจำเป็นต้องพิจารณาผลที่ได้ อย่างกรณีตัวอย่างนี้ แม้ผลจะสรุปว่าค่าเฉลี่ยไม่แตกต่างกัน แต่ภาพที่เรามองเห็นนั้นกำลังบอกว่า Machine 1 น่าจะได้รับการแก้ไขในบางอย่าง
กรณีที่เรากำหนดให้ D > 0 ในบางครั้งผลต่างในการทดสอบสมมติฐาน ของสองประชากรอาจจะไม่เท่ากับ 0 ก็ได้ ยกตัวอย่างต่อไปนี้ ตัวอย่าง ณ โรงงานผลิตชิ้นส่วนประกอบของรถยนต์แห่งหนึ่ง หัวหน้าฝ่ายวิศวกรรมต้องการปรับปรุงการทำงานของเครื่องตัดโลหะขนาดเส้นผ่าศูนย์กลาง 3 นิ้ว จำนวนทั้งหมด 6เครื่อง จะต้องใช้เงินลงทุนประมาณ 300,000 บาท ต่อเครื่อง แต่ผู้บริหารได้กำหนดไว้ว่าให้ปรับปรุงเพียงหนึ่งเครื่องก่อน และ ความสามารถของเครื่องในการตัดโลหะหลังจากปรับปรุงแล้วจะต้องเพิ่มขึ้นอย่างต่ำ 10 % ถึงจะถือว่าคุ้มทุนในการปรับปรุง และจะอนุมัติงบประมาณในการปรับปรุงเครื่องที่เหลือ วิศวกรที่รับผิดชอบจึงทำการเก็บข้อมูลความสามารถของเครื่อง โดยนับจำนวนชิ้นงานที่เครื่องตัดได้ภายในเวลา 1 ชั่วโมง( Unit per hour ) จำนวน 24 ชั่วโมง ( ตัวอย่าง ) ทั้งก่อนและหลังทำการปรับปรุงเครื่องตัดโลหะ ได้ข้อมูลดังต่อไปนี้
จากข้อมูลดังกล่าว พบว่าก่อนทำการปรับปรุงเครื่อง ความสามารถในการตัดโลหะของเครื่องโดยเฉลี่ย อยู่ที่ 557.4 ชิ้นต่อชั่วโมง ดังนั้นถ้าเพิ่มขึ้น 10% เท่ากับเพิ่มขึ้นประมาณ 55.74 ชิ้นต่อชั่วโมงโดยเฉลี่ย ให้ทำการทดสอบสมมติฐานว่า ความสามารถของเครื่องหลังทำการปรับปรุงแล้วเพิ่มขึ้น ตามข้อกำหนดของฝ่ายบริหารหรือไม่ ถ้าสมมติให้ขอ้มูลทั้งสองกลุ่มมีการกระจายเป็นแบบปกติ (Normal distribution ) และการกระจายของข้อมูลไม่มีความแตกต่างกัน และกำหนดระดับความเชื่อมั่นที่ 95% 1. หา Descriptive Statistics ของข้อมูลทั้งสองกลุ่ม ได้ดังนี้
2. กำหนดสมมติฐาน
หมายเหตุ : กำหนดให้ m1 คือ After และ m2 คือ Before เพราะ After มีค่าสูงกว่า 3. เลือกตัวทดสอบสมมติฐาน
4. หาค่า Sp จาก
Sp = 18.29 5. หาค่า Test statistic ( t0 ) เมื่อกำหนดให้ D > 0
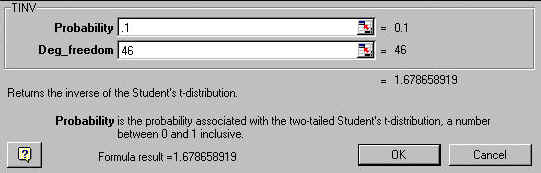
6. หา df จาก df = n1+n2-2 df= 24+24-2 =46 7. คำนวณหาค่า T-Critical ที่ a=0.05 , df=46 โดยใช้ MS Excel ได้ค่าเท่ากับ 1.678
(เนื่องจาก MS Excel จะมอง Probability เป็น a/2 เสมอ ดังนั้นเมื่อเราทดสอบด้านเดียว หรือ One-tailed test ค่า a ที่ใส่ต้องเอา 2 คูณก่อน) โดยใช้ Minitab ได้ค่าเท่ากับ -1.678 หรือ 1.678 แล้วแต่กรณีของ Alternative hypothesis Inverse Cumulative Distribution Function Student's t distribution with 46 DF P( X <= x ) x 0.0500 -1.6787
(เนื่องจาก Minitab จะให้ด้านซ้ายมือออกมา กรณีที่ Alternative hypothesis เป็นมากกว่า ก็ให้คิดค่าด้านบวก ของตัวเลขที่ คำนวณได้) 8. สรุปผลการทดสอบสมมุติฐานดังนี้ จะยอมรับสมมติฐาน Ho : m1 - m2 = D เมื่อ t0<ta,df ผลการทดสอบสมมติ t0= -2.32 , ta,df= 1.678 เราจึงยอมรับสมมติฐานหลัก หรือยอมรับว่า หลังจากทำการปรับปรุงเครื่องตัดโลหะแล้วความสามารถของเครื่องเพิ่มขึ้นไม่มากกว่า 10% ตามที่ฝ่ายบริหารกำหนดไว้ หากเราทดสอบสมมติฐานโดยใช้ MS Excel จะเป็นดังนี้ (โปรดอ่านวิธีใช้ Analysis tools สำหรับการทดสอบ 2 Mean )
เนื่องจากใน MS Excel จะกำหนด Alternative hypothesis เป็น น้อยกว่า เพียงอย่างเดียวในกรณีทดสอบด้านเดียว ดังนั้นเมื่อโจทย์ข้อนี้กำหนดให้ Alternative hypothesis เป็น มากกว่า เราจึงต้องคำนวณจาก P(T>t) = 1-P(T<=t) = 1-0.01246 = 0.97854 เมื่อ P(T>t) > a เราจึงยอมรับสมมติฐาน หลักที่ว่า Ho : m1 - m2 = D หมายความว่า หลังจากทำการปรับปรุงเครื่องตัดโลหะแล้วความสามารถของเครื่องเพิ่มขึ้นไม่มากกว่า 10% ตามที่ฝ่ายบริหารกำหนดไว้ หากเราทดสอบสมมติฐานโดยใช้ Minitab จะเป็นดังนี้ Two-sample T for After vs Before N Mean StDev SE Mean After 24 600.9 16.0 3.3 Before 24 557.4 20.3 4.1 Difference = mu After - mu Before Estimate for difference: 43.50 95% lower bound for difference: 34.64 T-Test of difference=55.74 (vs >):T-Value =-2.32 P-Value=0.988 DF=46 Both use Pooled StDev = 18.3
Minitab สามารถระบุการทดสอบเป็น มากกว่า ได้ ผลสรุปก็เหมือนกับการใช้ MS Excel คือ เมื่อ P-Value มากกว่า a เราจึงยอมรับสมมติฐานหลัก จากโจทย์ข้อนี้จะเห็นได้ว่า เมื่อเราระบุค่าความแตกต่างขึ้นมา ผลการทดสอบสมมติฐานก็จะแตกต่างออกไปจาก ที่เรากำหนดให้ความแตกต่างเท่ากับ 0
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||