|
ขั้นตอนการวิเคราะห์ Multiple Linear Regression ในหัวข้อนี้ จะศึกษาความสัมพันธ์ระหว่าง ตัวแปรตาม (Response , Dependent variable , Y ) หนึ่งตัวกับตัวแปรอิสระ (Predictor, Independent variable, X ) มากกว่าหนึ่งตัว แต่ความสัมพันธ์ดังกล่าวยังคงเป็นแบบเส้นตรงอยู่ ในชีวิตจริงแล้ว จะมีน้อยมากที่ปัจจัยหนึ่งจะขึ้นอยู่กับปัจจัยหนึ่งเพียงอย่างเดียว ส่วนมากแล้วตัวแปรตามมักจะขึ้นอยู่กับตัวแปรอิสระหลายตัว พูดง่ายๆภาษานักสถิติคือ Y มักจะขึ้นอยู่ X หลายตัว นั่นเอง ดังตัวอย่างต่อไปนี้ ตัวอย่าง 1 ในการจะศึกษาประสิทธิภาพการใช้น้ำมันของรถยนต์ เราไม่สามารถจะเอาขนาดของเครื่องยนต์มาเป็นตัวกำหนดเพียงอย่างเดียว จะต้องคำนึงถึงน้ำหนักตัวรถ น้ำหนักคนขับ อายุของเครื่องยนต์ ความเสียดทานต่อผิวถนนของล้อรถ พูดง่ายๆคือหากต้องการพยากรณ์อัตราความสิ้นเปลืองของน้ำมันเชื้อเพลิง หรืออัตราการใช้น้ำมัน (กิโลเมตร/ลิตร) แล้วจะต้องคำนึงถึงตัวแปรอิสระมากกว่าหนึ่งตัวแปร ตัวอย่างที่ 2 การจะศึกษาเพื่อพยากรณ์ปริมาณสารเคมีในกระแสเลือดของคนงานในโรงงานเคมี ตัวแปรอิสระที่ต้องใช้เป็นตัวคาดการณ์ จะประกอบด้วย Y : ปริมาณสารเคมีในกระแสเลือด X1 : จำนวนปีที่ทำงานอยู่กับสารเคมีนั้น X2 : จำนวนปี (เดือน หรือ สัปดาห์ ) ที่ออกห่างมาจากสถานที่ทำงานแบบนั้น X3 : อายุของคนงานนั้น X4 : น้ำหนักของคนงาน หรือดัชนีอื่นที่บ่งบอกถึงมวลกาย จะเห็น X ทั้งหมดล้วนเป็นปัจจัยที่จะทำให้สารเคมีเจือปนในกระแสเลือดมากน้อยได้ เช่น คนงานที่ทำงานมา 4 ปีกับ 1 ปี ย่อมได้รับสารเคมีในปริมาณที่ต่างกัน คนงานที่อายุ 22 ปีจะร่างกายจะยังมีความสามารถในการกำจัดสารแปลกปลอมในร่างกายได้ดีกว่าคนอายุ 35 ปี หรือคนที่ร่างกายใหญ่โตแข็งแรงก็จะมีขีดความสามารถในการจำกัดสิ่งแปลกปลอมในกระแสเลือดได้ดีกว่า คนตัวเล็ก คนผอม ตัวอย่างที่ 3 การจะวัดความฟิตของนักกีฬาสามารถวัดผ่านปริมาตรออกซิเจนที่ร่างกายใช้ต่อนาทีได้ แต่การจะวัดให้ได้อย่างแม่นยำนั้นไม่ใช่เรื่องง่ายและยังสิ้นเปลืองค่าใช้จ่ายที่สูงมาก แต่เราสามารถวัดโดยวิธีอ้อมได้ดังต่อไปนี้ Y : ปริมาตรออกซิเจนในการหายใจ (ลิตร/นาที) X1 : นำหนักของนักกีฬา (กิโลกรัม) X2 : อายุของนักกีฬา (ปี) X3 : ความสามารถในการเดิน โดยใช้ค่าเวลาที่เดินได้ 1 ไมล์ (นาที) X4 : อัตราการเต้นของหัวใจเมื่อเดินได้ 1 ไมล์ (ครั้ง/นาที) จากการวิจัยในสหรัฐอเมริกา ได้มีผลการศึกษาของมหาวิทยาลัยแห่งหนึ่งโดยทำการศึกษากับนักศึกษาจำนวนหนึ่ง โดยได้ตีพิมพ์ผลการศึกษาดังกล่าวในหัวข้อ " Validation of th Rockport Fitness Walking Test in College Male and Female " ( Reserach Quarterly for Excercise and Sport, 1994 : 152-158 ) โดยได้มีการนำเสนอสมการความสัมพันธ์ระหว่างตัวแปรทั้งหลายดังนี้ y = 5.0 + 0.01X1 - 0.05X2 - 0.13X3 - 0.01X4 หากนำ Regression model ดังกล่าวไปคาดการณ์ ปริมาตรออกซิเจนที่นักศักษาคนหนึ่งใช้ในการหายใจ โดยมีข้อมูลดังนี้ น้ำหนัก 76 กก. อายุ 20 ปี สามารถเดิน 1 ไมล์ได้โดยใช้เวลา 12 นาที และอัตราการเต้นของหัวใจเมื่อเดินได้ 1 ไมล์ดังกล่าวอยู่ที่ 140 ครั้งต่อนาที y = 5.0 + 0.01(76) - 0.05(20) - 0.13(12) - 0.01(140) y = 1.80 ลิตร/นาที ซึ่งการจะสรุปผล Fitness ของนักศึกษาคนนี้อยู่ในเกณฑ์ใด ก็นำค่า y = 1.80 ลิตร/นาที ไปเปรียบเทียบกับตารางมาตรฐานอีกทีหนึ่ง ทั้ง 3 ตัวอย่างนั้น เป็นเพียงตัวอย่างง่ายๆ เพื่อชี้ให้ท่านผู้อ่านได้เข้าใจว่า Multiple Linear Regression คืออะไรและใช้อะไรได้บ้าง โดยทั่วไปในความสัมพันธ์นั้นจะมีตัวแปรต้นอยู่หลายตัว แต่ผู้เขียนขอยกตัวอย่างและแสดงขั้นตอนการวิเคราะห์กรณีที่มีตัวแปรต้นเพียงสองตัวโดยรูปแบบความสัมพันธ์หรือ Regression model จะเป็นดังนี้
เมื่อ e คือ Error ของ Model ซึ่งจะมีค่าเข้าหา 0 (ไม่มี Error) ซึ่งเราจะมองเป็น Normal distribution ที่อยู่รอบๆค่า 0 และมี variance อยู่ค่าหนึ่ง เมื่อเราใช้ Least square method จะได้สมการความสัมพันธ์ดังต่อไปนี้ (ผู้เขียนขอไม่กล่าวถึงที่ไปที่มาของสมการเหล่านี้)
ตัวอย่าง มีข้อมูลดังตารางที่ 1 เมื่อต้องการวิเคราะห์ Multiple linear regression มีขั้นตอนดังนี้
ตารางที่ 1 ขั้นตอนที่ 1 หาสมการที่จะใช้คำนวณ จากตารางที่ 1 มีตัวแปรต้นหรือตัวแปรอิสระ(X) อยู่สองตัว จำนวนข้อมูล (n) 10 ข้อมูล ดังนั้น Regression model จึงมีค่าคงที่และสัมประสิทธิ์ของตัวแปรอิสระที่ต้องหา คือ b0,b1 และ b2 โดยสมการที่ใช้หาจึงเป็นดังต่อไปนี้
ขั้นตอนที่ 2 คำนวณหาค่าเพื่อแทนลงในสมการ จากตารางที่ 1 เราจะทำการคำนวณค่าต่างๆตามสมการทั้งสาม โดยใช้ตาราง Excel ช่วยในการคำนวณ ซึ่งจะไดดังตารางที่ 2
ตารางที่ 2 จากกตารางที่ 2 เมื่อนำค่าที่ได้ใส่สมการทั้งสาม จะได้สมการใหม่ 3 สมการเรียงลำดับดังนี้
วิธีที่สามารถใช้ในการแก้สมการ เพื่อหาค่า b0,b1 และ b2 นั้นมีอยู่หลายวิธี แต่ผู้เขียนขอเลือกใช้วิธี Matrix ในการแก้สมการเพื่อหาคำตอบ ซึ่งท่านสามารถอ่านวิธีการ Matrix เพื่อเป็นตัวอย่างได้ ทางนี้ <<< Link To Matrix >>> ขั้นตอนที่ 3 เปลี่ยนสมการให้อยู่ในรูป Matrix แล้วใช้วิธีการทาง Matrix ในการหาค่า b0,b1 และ b2 จะได้สมการในรูป
เมื่อแทนค่าแล้วจะได้ Matrix เป็น
เมื่อทำการหา Inverse matrix จะได้ Matrix เป็นดังต่อไปนี้ (ผู้อ่านควรทำความเข้าใจหลักการคูณกันของ Matrix ด้วย)
ดังนั้นสมการหรือ Regression model ที่ได้จะเป็น
ขั้นตอนที่ 4 ทดสอบสมมติฐาน เพื่อหาว่าค่า b0,b1 และ b2 ที่หามาได้นั้นมีนัยสำคัญความแตกต่างกับ 0 หรือไม่ พูดง่ายๆคือจำเป็นต้องคงค่า หรือพจน์ที่ค่านี้คูณอยู่ไว้ใน Model หรือไม่ โดยสมมติฐานที่ต้องทดสอบคือ
ในการทดสอบ จะใช้ T -Statistics ทั้งนี้เพราะเรา Assume ว่า ค่า b0, b1 และ b2จะเป็น Normal distribution รอบๆค่ากลางค่าหนึ่ง เรากำลังจะทดสอบว่าค่ากลางดังกล่าวเท่ากับ 0 หรือไม่ โดยสมการในการหาค่า T เป็นดังนี้ (ผู้เขียนขอไม่อธิบายที่มาของสมการ)
เมื่อ (sbi )2 : Estimated Standard Error Cbi : ค่าที่ได้มาจาก Inverse matrix [A]-1 ตามแนวทะแยงมุม ที่ตรงกับ bi นั้นๆ n : No of observation p : No of regressor (b0 , b1 .... bk ) ตัวอย่างนี้ คือ 3 จากตารางที่ 2
จาก Inverse matrix ค่าตามแนวทะแยงลง จะได้
ดังนั้นจะได้
ถ้ากำหนด a = 0.05 เมื่อเปิดตาราง T เพื่อหาค่าวิกฤติ จะได้
เราจะปฏิเสธสมมติฐานหลัก ถ้าค่า tb ที่คำนวณได้มากกว่า tb วิกฤติที่หาได้จากตาราง T ดังนั้นสมมติฐานหลักทั้งสามจึงไม่เป็นจริง นั่นคือ ค่า b0, b1 และ b2 มีค่าไม่เท่ากับ 0 จริง จึงไม่สามารถตัดออกจาก Regression model ได้ ขั้นตอนที่ 5 การพิสูจน์ว่า Regression model ที่ได้มานั้นเหมาะที่จะนำไปใช้คาดการณ์ ( Predict ) ค่า Y ในอนคตมากน้อยเพียงใด ซึ่งจะใช้วิธีพิสูจน์ค่าความคลาดเคลื่อน (Error) ตัวสถิติที่จะใช้ทดสอบความคลาดเคลื่อนนี้ เราเรียกว่า F-Statistic และสมมติฐานคือ H0 : Error จากการใช้ Model นี้ Predict ค่า Y เป็น Error ที่ไม่สามารถอธิบายได้เป็นส่วนใหญ่ Ha: Error จากการใช้ Model นี้ Predict ค่า Y เป็น Error ที่สามารถอธิบายได้เป็นส่วนใหญ่ สมการทางคณิตศาสตร์ที่ใช้ในการคำนวณ มีดังนี้
ค่า degree of freedom หาได้จาก Total = n-1 = 10-1 = 9 Error = n - p = 10 - 3 = 7 Regression = k = Total - Error = 9 - 7 = 2
หาค่า F-critical จากตาราง F
สมมติฐานหลักจะไม่เป็นจริง ถ้าค่า F ที่คำนวณได้ มากกว่า F-critical ที่ได้จากตาราง ดังนั้นกรณีนี้เราจึงปฏิเสธสมมติฐานหลัก นั่นคือ Error ของ Model นี้ส่วนใหญ่สามารถอธิบายได้ (เกิดจากการเปลี่ยนค่า X1 หรือ X2 ) มากกว่าจะเกิดจากเหตุอื่นๆ จึงสรุปว่า Regression model นี้ ให้ความแม่นยำสูงถ้านำไปพยากรณ์ค่า Y ขั้นตอนที่ 6 การหา Coefficient of Determination
พบว่า ค่า R2 มีค่าสูงมาก R2-adjusted ก็ต่ำกว่า R2 ไม่มาก สรุปว่า Error ที่เราไม่สามารถอธิบายได้มีมากกว่า Error ที่เราไม่สามารถอธิบายที่มาได้ ในอัตราส่วนที่มากทีเดียว และจำนวนสิ่งตัวอย่างที่เก็บมานั้นก็อยู่ในเกณฑ์มาตรฐาน หากนำค่าที่ได้จากการคำนวณมาเขียนสรุปเป็นตารางจะได้ดังต่อไปนี้
ตารางที่ 3 ในกรณีที่เราใช้โปรแกรม Microsoft Excel ช่วยในการวิเคราะห์ จะได้ตารางออกมาดังต่อไปนี้
ตารางที่ 4 ขั้นตอนที่ 7 การพิสูจน์คุณสมบัติ 3 ประการ โดยกราฟที่ได้จากโปรแกรม Excel - Normality
จากกราฟ การเรียงตัวของจุดค่า Y เทียบกับ Percentile เป็นแนว แม้จะไม่เป็นเส้นตรงเสียทีเดียว แต่สามารถยอมรับได้ว่าเป็น Normal distribution ได้ - Independence
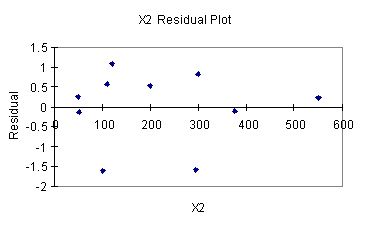
จะพบว่า แนวของจุดถือได้ว่า ไม่มีทิศทางใดแน่นอน ไม่ได้อยู่ทางด้านลบหรือบวกอย่างเดียว ไม่ได้ขึ้นหรือลงอย่างเดียว ลักษณะเช่นนี้เราถือว่าความเป็นอิสระของ X แต่ละตัวอยู่ในเกณฑ์ที่ยอมรับได้ (กรณี Multiregression Analysis โปรแกรม Excel ไม่ได้พล้อตให้ ท่านจำเป็นต้องทำเอง) - Homoscedasticity
เมื่อทำการพล้อต Residual กับค่า X (Fit) ทั้งสอง (X) พบว่าจุดไม่มีลักษณะอยู่ด้านบวก หรือลบตลอด หรือเป็น 0 ตลอด หรือกว้างออกตลอด เมื่อค่า X สูงขึ้นหรือต่ำลง เราพอจะอนุมานได้ว่า Residual ตลอดย่านค่า X ไม่ได้แตกต่างกันจนเกินเหตุ นั่นคือการเพิ่มหรือลดค่า X ไม่ได้ทำให้ความคลาดเคลื่อนหรือ Error ของ Regression model เปลี่ยนไปจนเกินเหตุ เราจะถือว่าผ่านเงื่อนไขนี้ (แยกวิเคราะห์แต่ละ X ) จะเห็นว่า แม้จะมีตัวแปรต้น(อิสระ) หรือ X มากกว่าหนึ่งตัว แต่เราก็ยังใช้วิธีวิเคราะห์เหมือนกัน แตกต่างกันเฉพาะรายละเอียดเท่านั้น
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||